Airflow — инструмент, чтобы удобно и быстро разрабатывать и поддерживать batch-процессы обработки данных
Привет, Хабр! В этой статье я хочу рассказать об одном замечательном инструменте для разработки batch-процессов обработки данных, например, в инфраструктуре корпоративного DWH или вашего DataLake. Речь пойдет об Apache Airflow (далее Airflow). Он несправедливо обделен вниманием на Хабре, и в основной части я попытаюсь убедить вас в том, что как минимум на Airflow стоит смотреть при выборе планировщика для ваших ETL/ELT-процессов.
Ранее я писал серию статей на тему DWH, когда работал в Тинькофф Банке. Теперь я стал частью команды Mail.Ru Group и занимаюсь развитием платформы для анализа данных на игровом направлении. Собственно, по мере появления новостей и интересных решений мы с командой будем рассказывать тут о нашей платформе для аналитики данных.
Пролог
Итак, начнем. Что такое Airflow? Это библиотека (ну или набор библиотек) для разработки, планирования и мониторинга рабочих процессов.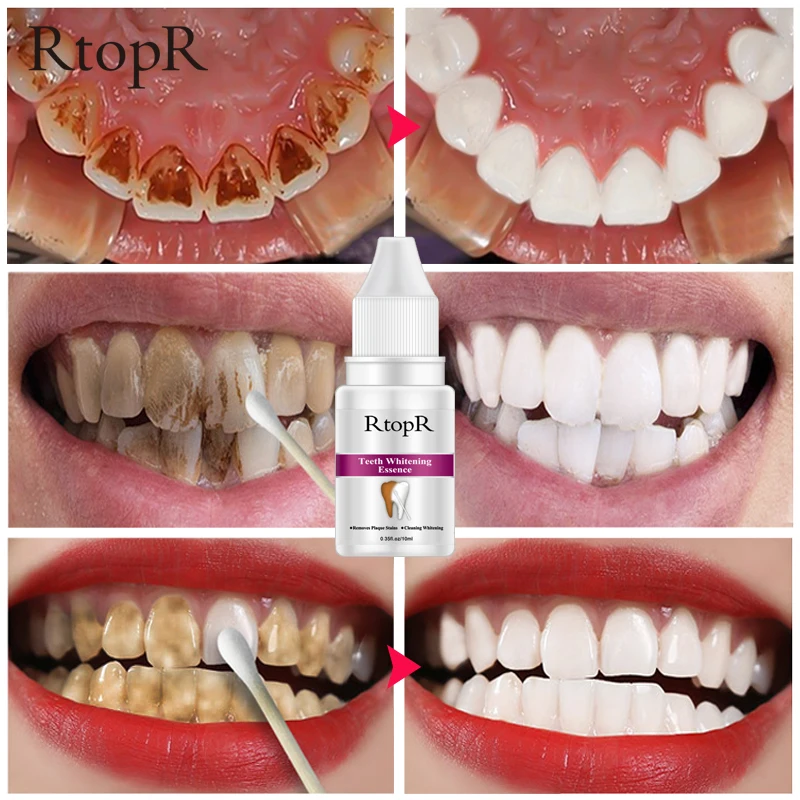 Основная особенность Airflow: для описания (разработки) процессов используется код на языке Python. Отсюда вытекает масса преимуществ для организации вашего проекта и разработки: по сути, ваш (например) ETL-проект — это просто Python-проект, и вы можете его организовывать как вам удобно, учитывая особенности инфраструктуры, размер команды и другие требования. Инструментально всё просто. Используйте, например, PyCharm + Git. Это прекрасно и очень удобно!
Основная особенность Airflow: для описания (разработки) процессов используется код на языке Python. Отсюда вытекает масса преимуществ для организации вашего проекта и разработки: по сути, ваш (например) ETL-проект — это просто Python-проект, и вы можете его организовывать как вам удобно, учитывая особенности инфраструктуры, размер команды и другие требования. Инструментально всё просто. Используйте, например, PyCharm + Git. Это прекрасно и очень удобно!
Теперь рассмотрим основные сущности Airflow. Поняв их суть и назначение, вы оптимально организуете архитектуру процессов. Пожалуй, основная сущность — это Directed Acyclic Graph (далее DAG).
DAG
DAG — это некоторое смысловое объединение ваших задач, которые вы хотите выполнить в строго определенной последовательности по определенному расписанию. Airflow представляет удобный web-интерфейс для работы с DAG’ами и другими сущностями:
DAG может выглядеть таким образом:
Разработчик, проектируя DAG, закладывает набор операторов, на которых будут построены задачи внутри DAG’а. Тут мы приходим еще к одной важной сущности: Airflow Operator.
Тут мы приходим еще к одной важной сущности: Airflow Operator.
Операторы
Оператор — это сущность, на основании которой создаются экземпляры заданий, где описывается, что будет происходить во время исполнения экземпляра задания. Релизы Airflow с GitHub уже содержат набор операторов, готовых к использованию. Примеры:
- BashOperator — оператор для выполнения bash-команды.
- PythonOperator — оператор для вызова Python-кода.
- EmailOperator — оператор для отправки email’а.
- HTTPOperator — оператор для работы с http-запросами.
- SqlOperator — оператор для выполнения SQL-кода.
- Sensor — оператор ожидания события (наступления нужного времени, появления требуемого файла, строки в базе БД, ответа из API — и т. д., и т. п.).
Есть более специфические операторы: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Вы также можете разрабатывать операторы, ориентируясь на свои особенности, и использовать их в проекте.
Далее все эти экземпляры задачек нужно выполнять, и теперь речь пойдет о планировщике.
Планировщик
Планировщик задач в Airflow построен на Celery. Celery — это Python-библиотека, позволяющая организовать очередь плюс асинхронное и распределенное исполнение задач. Со стороны Airflow все задачи делятся на пулы. Пулы создаются вручную. Как правило, их цель — ограничить нагрузку на работу с источником или типизировать задачи внутри DWH. Пулами можно управлять через web-интерфейс:
Каждый пул имеет ограничение по количеству слотов. При создании DAG’а ему задается пул:
При создании DAG’а ему задается пул:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh") DAG_NAME = 'dma_load' OWNER = 'Vasya Pupkin' DEPENDS_ON_PAST = True EMAIL_ON_FAILURE = True EMAIL_ON_RETRY = True RETRIES = int(Variable.get('gv_dag_retries')) POOL = 'dma_pool' PRIORITY_WEIGHT = 10 start_dt = datetime.today() - timedelta(1) start_dt = datetime(start_dt.year, start_dt.month, start_dt.day) default_args = { 'owner': OWNER, 'depends_on_past': DEPENDS_ON_PAST, 'start_date': start_dt, 'email': ALERT_MAILS, 'email_on_failure': EMAIL_ON_FAILURE, 'email_on_retry': EMAIL_ON_RETRY, 'retries': RETRIES, 'pool': POOL, 'priority_weight': PRIORITY_WEIGHT } dag = DAG(DAG_NAME, default_args=default_args) dag.doc_md = __doc__
Пул, заданный на уровне DAG’а, можно переопределить на уровне задачи.
За планировку всех задач в Airflow отвечает отдельный процесс — Scheduler. Собственно, Scheduler занимается всей механикой постановки задачек на исполнение.
- В DAG’е выполнены предыдущие задачи, новую можно поставить в очередь.
- Очередь сортируется в зависимости от приоритета задач (приоритетами тоже можно управлять), и, если в пуле есть свободный слот, задачу можно взять в работу.
- Если есть свободный worker celery, задача направляется в него; начинается работа, которую вы запрограммировали в задачке, используя тот или иной оператор.
Достаточно просто.
Scheduler работает на множестве всех DAG’ов и всех задач внутри DAG’ов.
Чтобы Scheduler начал работу с DAG’ом, DAG’у нужно задать расписание:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')Есть набор готовых preset’ов: @once, @hourly, @daily, @weekly, @monthly, @yearly.
Также можно использовать cron-выражения:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')Execution Date
Чтобы разобраться в том, как работает Airflow, важно понимать, что такое Execution Date для DAG’а. В Airflow DAG имеет измерение Execution Date, т. е. в зависимости от расписания работы DAG’а создаются экземпляры задачек на каждую Execution Date. И за каждую Execution Date задачи можно выполнить повторно — или, например, DAG может работать одновременно в нескольких Execution Date. Это наглядно отображено здесь:
В Airflow DAG имеет измерение Execution Date, т. е. в зависимости от расписания работы DAG’а создаются экземпляры задачек на каждую Execution Date. И за каждую Execution Date задачи можно выполнить повторно — или, например, DAG может работать одновременно в нескольких Execution Date. Это наглядно отображено здесь:
К сожалению (а может быть, и к счастью: зависит от ситуации), если правится реализация задачки в DAG’е, то выполнение в предыдущих Execution Date пойдет уже с учетом корректировок. Это хорошо, если нужно пересчитать данные в прошлых периодах новым алгоритмом, но плохо, потому что теряется воспроизводимость результата (конечно, никто не мешает вернуть из Git’а нужную версию исходника и разово посчитать то, что нужно, так, как нужно).
Генерация задач
Реализация DAG’а — код на Python, поэтому у нас есть очень удобный способ сократить объем кода при работе, например, с шардированными источниками. Пускай у вас в качестве источника три шарда MySQL, вам нужно слазить в каждый и забрать какие-то данные.
connection_list = lv.get('connection_list') export_profiles_sql = ''' SELECT id, user_id, nickname, gender, {{params.shard_id}} as shard_id FROM profiles ''' for conn_id in connection_list: export_profiles = SqlToHiveViaHdfsTransfer( task_id='export_profiles_from_' + conn_id, sql=export_profiles_sql, hive_table='stg.profiles', overwrite=False, tmpdir='/data/tmp', conn_id=conn_id, params={'shard_id': conn_id[-1:], }, compress=None, dag=dag ) export_profiles.set_upstream(exec_truncate_stg) export_profiles.set_downstream(load_profiles)
DAG получается таким:
При этом можно добавить или убрать шард, просто скорректировав настройку и обновив DAG. Удобно!
Можно использовать и более сложную генерацию кода, например работать с источниками в виде БД или описывать табличную структуру, алгоритм работы с таблицей и с учетом особенностей инфраструктуры DWH генерировать процесс загрузки N таблиц к вам в хранилище. Или же, например, работу с API, которое не поддерживает работу с параметром в виде списка, вы можете сгенерировать по этому списку N задач в DAG’е, ограничить параллельность запросов в API пулом и выгрести из API необходимые данные. Гибко!
Или же, например, работу с API, которое не поддерживает работу с параметром в виде списка, вы можете сгенерировать по этому списку N задач в DAG’е, ограничить параллельность запросов в API пулом и выгрести из API необходимые данные. Гибко!
Репозиторий
В Airflow есть свой бекенд-репозиторий, БД (может быть MySQL или Postgres, у нас Postgres), в которой хранятся состояния задач, DAG’ов, настройки соединений, глобальные переменные и т. д., и т. п. Здесь хотелось бы сказать, что репозиторий в Airflow очень простой (около 20 таблиц) и удобный, если вы хотите построить какой-либо свой процесс над ним. Вспоминается 100500 таблиц в репозитории Informatica, которые нужно было долго вкуривать, прежде чем понять, как построить запрос.
Мониторинг
Учитывая простоту репозитория, вы можете сами построить удобный для вас процесс мониторинга задачек. Мы используем блокнот в Zeppelin, где смотрим состояние задач:
Это может быть и web-интерфейс самого Airflow:
Код Airflow открыт, поэтому мы у себя добавили алертинг в Telegram. Каждый работающий инстанс задачи, если происходит ошибка, спамит в группу в Telegram, где состоит вся команда разработки и поддержки.
Каждый работающий инстанс задачи, если происходит ошибка, спамит в группу в Telegram, где состоит вся команда разработки и поддержки.
Получаем через Telegram оперативное реагирование (если такое требуется), через Zeppelin — общую картину по задачам в Airflow.
Итого
Airflow в первую очередь open source, и не нужно ждать от него чудес. Будьте готовы потратить время и силы на то, чтобы выстроить работающее решение. Цель из разряда достижимых, поверьте, оно того стоит. Скорость разработки, гибкость, простота добавления новых процессов — вам понравится. Конечно, нужно уделять много внимания организации проекта, стабильности работы самого Airflow: чудес не бывает.
Сейчас у нас Airflow ежедневно отрабатывает около 6,5 тысячи задач. По характеру они достаточно разные. Есть задачи загрузки данных в основное DWH из множества разных и очень специфических источников, есть задачи расчета витрин внутри основного DWH, есть задачи публикации данных в быстрое DWH, есть много-много разных задач — и Airflow все их пережевывает день за днем. Если же говорить цифрами, то это 2,3 тысячи ELT задач различной сложности внутри DWH (Hadoop), около 2,5 сотен баз данных источников, это команда из 4-ёх ETL разработчиков, которые делятся на ETL процессинг данных в DWH и на ELT процессинг данных внутри DWH и конечно ещё одного админа, который занимается инфраструктурой сервиса.
Если же говорить цифрами, то это 2,3 тысячи ELT задач различной сложности внутри DWH (Hadoop), около 2,5 сотен баз данных источников, это команда из 4-ёх ETL разработчиков, которые делятся на ETL процессинг данных в DWH и на ELT процессинг данных внутри DWH и конечно ещё одного админа, который занимается инфраструктурой сервиса.
Планы на будущее
Количество процессов неизбежно растет, и основное, чем мы будем заниматься в части инфраструктуры Airflow, — это масштабирование. Мы хотим построить кластер Airflow, выделить пару ног для worker’ов Celery и сделать дублирующую себя голову с процессами планировки заданий и репозиторием.
Эпилог
Это, конечно, далеко не всё, что хотелось бы рассказать об Airflow, но основные моменты я постарался осветить. Аппетит приходит во время еды, попробуйте — и вам понравится 🙂
эффективное удаление налета. Цена услуги в Москве
Что такое чистка зубов Air Flow?
Air Flow — это метод профессиональной чистки зубов с помощью специального аппарата и воздушно-водно-порошковой смеси. Этот состав прекрасно справляется с удалением зубного налета.
Этот состав прекрасно справляется с удалением зубного налета.
Налет образуется на зубах, когда мы едим, пьем чай или кофе. Не всегда зубной налет можно удалить при домашней чистке зубов. Особенно показана такая процедура людям со скученностью зубов, а также тем, кто носит брекеты. В этих случаях проводить надлежащую гигиену в домашних условиях бывает сложно.
Чистка зубов Air Flow – один из этапов профессиональной гигиены полости рта, наряду с удалением зубного камня, ремотерапией или фторированием. Процедура абсолютно комфортна и безопасна.
В каких случаях нужна процедура Air Flow?
- Для удаления налёта и пигментации (от кофе, чая, сигарет, красного вина, некоторых видов красящих фруктов, овощей и специй)
- Перед терапевтическим лечением (начинающийся кариес можно увидеть, только предварительно убрав налет с зубов)
- Для профилактики заболеваний пародонта (микробный налёт провоцирует развитие патологических процессов)
- Перед протезированием или установкой
- Перед установкой брекет-системы и после снятия
- Для очищения таких видов реставраций, как виниры, коронки
- Перед отбеливанием.


Профессиональная гигиена – эффективная профилактика кариеса, поэтому эти процедуры должны стать регулярными. Индивидуальный график составит ваш лечащий врач. В среднем — это 1 раз в 6 месяцев.
Наши счастливые пациенты. Результат профессиональной гигиены
Как происходит чистка зубов Air Flow?
Чистка зубов AIR FLOW проходит с помощью аппарата, через который подается воздушно-водно-порошковая смесь. Чтобы раствор не попал в глаза, на пациента надевают защитные очки. Стоматологический гигиенист аккуратно снимает налет с зубов, а ассистент вовремя удаляет из полости рта отработанный порошок. В заключении процедуры Air Flow наносится защитный фторирующий гель, позволяющий снизить чувствительность и укрепить эмаль. После чистки зубов Air Flow в течение нескольких часов рекомендовано не употреблять пищу и напитки с ярким пигментом, отказаться от курения.
Air Flow не повредит зубную эмаль?
Очень важно, каким порошком производится очистка эмали — Air Flow. Мы используем инновационный мельчайший порошок Эритритол. Он не меняет структуру эмали. С помощью этого порошка мы удалим налет максимально аккуратно и качественно.
Мы используем инновационный мельчайший порошок Эритритол. Он не меняет структуру эмали. С помощью этого порошка мы удалим налет максимально аккуратно и качественно.Наталья07 января 2021
Благодарю Ольгу Валентиновну за отличную работу! В каждом движении и слове помимо профессионализма чувствуется искренняя забота, что особо ценно в наше время. Процедура прошла комфортно с учётом того, что у меня повышенная чувствительность некоторых зубов. Понравилась подробная консультация и расширенные рекомендации касательно домашнего ухода. С удовольствием приду ещё и буду рекомендовать знакомым. Отдельное спасибо ассистенту Надежде, администраторам и координатору Екатерине за грамотную и четкую организацию.Читать отзывы
Екатерина Максимова05 января 2021
Благодарю Константина Склярова за блестяще проведённую профгигиену! Константин — профессионал-волшебник! Очень доброжелательный, внимательный, аккуратный и спокойный доктор. Работу выполнил качественно, без суеты, подробно рассказал об исходном состоянии зубов, проводимых процедурах, показал дополнительные приёмы ухода за полостью рта. Константин, спасибо Вам за отличный результат, полезную информацию и заботливое отношение! Успехов Вам и дальнейшего развития в профессии! Будьте всегда таким же классным специалистом! 🙂
Работу выполнил качественно, без суеты, подробно рассказал об исходном состоянии зубов, проводимых процедурах, показал дополнительные приёмы ухода за полостью рта. Константин, спасибо Вам за отличный результат, полезную информацию и заботливое отношение! Успехов Вам и дальнейшего развития в профессии! Будьте всегда таким же классным специалистом! 🙂КОМАНДА BELGRAVIA DENTAL STUDIO: Екатерина, спасибо вам за теплые слова! Мы очень рады, что вам понравилась профгигиена. Приходите снова, всегда готовы вам помочь!
Читать отзывы
Радмила 07 декабря 2020
Хочу выразить большую благодарность врачу Константину Александровичу и его ассистенту за мои блестящие, чистейшие зубки Была на процедуре чистки, а эффект, как-будто еще и отбелили, очень довольна!! В очень приятной, весёлой атмосфере, быстро и с полной консультацией, без вопросов высший уровень! Благодаря врачам этой клиники, перестала бояться стоматологов, теперь любая процедура только в радость проходит!) Спасибо!!!КОМАНДА BELGRAVIA DENTAL STUDIO: мы рады, что у вас такой отличный результат! Мы очень много делаем для этого, закупаем новое оборудование для профгигиены, используем самые современные материалы, специальные порошки, которые не портят эмаль, но при этом чистят идеально. Спасибо большое вам за отзыв! Приходите снова!
Спасибо большое вам за отзыв! Приходите снова!
Читать отзывы
Сара03 декабря 2020
Выражаю благодарность гигиенисту Гречухиной Екатерине Владимировне за жемчужную красоту и свежесть моим зубкам! Гигиена прошла максимально безболезненно и даже приятно, благодаря новейшему оборудованию, легким ручкам Екатерины Владимировны и ассистента Дарьи , внимательные и очень аккуратные! Были даны рекомендации и обучение по домашнему уходу, выборе зубной щётки и пасты. СПАСИБО БОЛЬШОЕ! Очень рекомендую!КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв и готовность нас рекомендовать! Да, мы прилагаем очень много усилий, чтобы любая процедура в нашей клинике была без стресса. Это касается и гигиены, и лечения. Спасибо, что оценили это!
Читать отзывы
Владислав13 ноября 2020
Второй раз был на приеме у доктора Коготько О. В. и второй раз очень доволен результатом. Доктор все сделала очень бережно и тщательно, ни одного намека на болевые ощущения, самые настоящие «легкие руки». Во время и после процедуры получил полнейший инструктаж по уходу за зубами. Смело рекомендую доктора своим знакомым!
В. и второй раз очень доволен результатом. Доктор все сделала очень бережно и тщательно, ни одного намека на болевые ощущения, самые настоящие «легкие руки». Во время и после процедуры получил полнейший инструктаж по уходу за зубами. Смело рекомендую доктора своим знакомым!КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв! У Ольги Валентиновны действительно легкие и нежные руки, согласны с вами! Крепкого здоровья, всегда рады помочь!
Читать отзывы
Екатерина 04 ноября 2020
Оленина Екатерина Валентиновна вы теперь моя зубная фея! Огромное спасибо за необыкновенные 1,5 часа! Посмотрела фильм во время чистки, без каких либо неприятных ощущений и с необыкновенной заботой зубной феи Екатерины. Я даже и не ожидала, что можно добиться такого результата красивых и чистых зубов. Столько полезной информации и подарков не только для меня, но и для дочки. Как жаль, что я раньше не знала про такую замечательную клинику и необыкновенных специалистов.
КОМАНДА BELGRAVIA DENTAL STUDIO: как хорошо, что вы теперь с нами! Да, мы относимся к профгигиене так же серьезно, как и к лечению. При этом делаем все бережно и нежно. Спасибо большое, что вы все это заметили! Всегда рады вам помочь!
Читать отзывы
Катерина26 сентября 2020
Обратилась к Екатерине Владимировне с кровоточивостью дёсен. Доктор провела чистку очень качественно. После чистки грамотно указала на ошибки допущенные при самостоятельной гигиене полости рта и проконсультировала как их избегать в дальнейшем. Через два дня после посещения доктора кровоточивость полностью исчезла! Большое спасибо за профессионально оказанную помощь! А ещё у Екатерины Владимировны очень нежные руки!КОМАНДА BELGRAVIA DENTAL STUDIO: благодарим вас за отзыв! Мы очень рады, что помогли вам справиться с проблемой! Нежные руки — это крайне важно для стоматолога 🙂 Крепкого здоровья, мы всегда будем рады вам помочь!
Читать отзывы
Екатерина 22 сентября 2020
Выражаю свою огромную благодарность гигиенисту Гончаровой Валерии Владимировне , за ее нежные руки, за доброе отношение к пациентам, за умение, и квалифицированный подход! Рекомендую этого замечательного специалиста, мастера своего дела!КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за такие теплые слова! Обязательно передадим их Валерии Владимировне! А вам — крепкого здоровья!
Читать отзывы
Ольга31 июля 2020
«Было бы счастье, да несчастье помогло»… Потеряла зуб, коронку на штифте и решилась обратиться в клинику, о которой мечтала, но откладывала посещение очень долго. Путь по лечению и восстановлению будет долгим. И я очень счастлива, что первый мой прием был у Ольги Валентиновны Коготько. Так как она, никто ранее, никогда и ни где не проводил мне гигиену! Помимо потрясающего результата (моя семья и коллеги по работе сразу отметили посветлевшие зубы, и это без отбеливания), я хочу отметить ласковое, спокойное, не критикующее отношение ко мне. Имея за спиной кое какую практику лечения в «модной» стоматологии, я поняла, как отстали технологии в них… Моя история в Вашей клинике началась с Ольги Валентиновны и я невероятно удивлена высоким профессионализмом и умением психологически управлять, успокоить пациента. И как ни странно, она научила меня просто дышать во время уже совсем не утомительной процедуры)) И я уже жду, когда придет время снова лечь в кресло Ольги Валентиновны)) Браво! И спасибо милому ангелу ассистенту!КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв! Мы очень рады работать с вами и всегда готовы помочь!
Читать отзывы
Виктория07 июля 2020
Хочу выразить огромную благодарность доктору Гречухиной Екатерине Владимировне за профессиональный подход и бережное лечение!Процедура профессиональной чистки была безболезненной и качественной. Очень аккуратный и внимательный доктор! Результат потрясающий, даже не нужно делать отбеливание! В клинике очень приятная атмосфера и прекрасный сервис! Всем буду рекомендовать только вас!КОМАНДА BELGRAVIA DENTAL STUDIO: Виктория, благодарим за отзыв и за готовность рекомендовать нас! Очень рады, что помогли вам, всегда рады видеть вас в нашей клинике!
Читать отзывы
Анна20 июня 2020
Выражаю огромную благодарность Гончаровой В.В . Доктор провела гигиеническую чистку очень чувствительных зубов совсем безболезненно! Я очень рада , что попала именно к Вам. Раньше очень тяжело сидела на этой процедуре в другой клинике. Теперь на чистку только к ней) . Все прошло очень комфортно , без дискомфорта. Валерия Владимировна рассказала мне о важных рекомендациях по уходу за зубами , чему ей очень благодарна!!!КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое! мы очень рады, что помогли вам! Да,, действительно, мы знаем, как превратить профгигиену с приятную spa-процедуру для зубов. Всегда вам рады!
Читать отзывы
Благодарю Ольгу Валентиновну за отличную работу! В каждом движении и слове помимо профессионализма чувствуется искренняя забота, что особо ценно в наше время. Процедура прошла комфортно с учётом того, что у меня повышенная чувствительность некоторых зубов. Понравилась подробная консультация и расширенные рекомендации касательно домашнего ухода. С удовольствием приду ещё и буду рекомендовать знакомым. Отдельное спасибо ассистенту Надежде, администраторам и координатору Екатерине за грамотную и четкую организацию.КОМАНДА BELGRAVIA DENTAL STUDIO: Наталья, спасибо вам за теплые слова в адрес доктора и всей нашей команды! Да, мы даем подробные рекомендации, потому что считаем правильный домашний уход очень важным! Всегда рады вам помочь и благодарим за готовность нас рекомендовать!
КОМАНДА BELGRAVIA DENTAL STUDIO: Екатерина, спасибо вам за теплые слова! Мы очень рады, что вам понравилась профгигиена. Приходите снова, всегда готовы вам помочь!
КОМАНДА BELGRAVIA DENTAL STUDIO: мы рады, что у вас такой отличный результат! Мы очень много делаем для этого, закупаем новое оборудование для профгигиены, используем самые современные материалы, специальные порошки, которые не портят эмаль, но при этом чистят идеально. Спасибо большое вам за отзыв! Приходите снова!
КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв и готовность нас рекомендовать! Да, мы прилагаем очень много усилий, чтобы любая процедура в нашей клинике была без стресса. Это касается и гигиены, и лечения. Спасибо, что оценили это!
КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв! У Ольги Валентиновны действительно легкие и нежные руки, согласны с вами! Крепкого здоровья, всегда рады помочь!
КОМАНДА BELGRAVIA DENTAL STUDIO: как хорошо, что вы теперь с нами! Да, мы относимся к профгигиене так же серьезно, как и к лечению. При этом делаем все бережно и нежно. Спасибо большое, что вы все это заметили! Всегда рады вам помочь!
КОМАНДА BELGRAVIA DENTAL STUDIO: благодарим вас за отзыв! Мы очень рады, что помогли вам справиться с проблемой! Нежные руки — это крайне важно для стоматолога 🙂 Крепкого здоровья, мы всегда будем рады вам помочь!
КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за такие теплые слова! Обязательно передадим их Валерии Владимировне! А вам — крепкого здоровья!
КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое за отзыв! Мы очень рады работать с вами и всегда готовы помочь!
КОМАНДА BELGRAVIA DENTAL STUDIO: Виктория, благодарим за отзыв и за готовность рекомендовать нас! Очень рады, что помогли вам, всегда рады видеть вас в нашей клинике!
КОМАНДА BELGRAVIA DENTAL STUDIO: спасибо вам большое! мы очень рады, что помогли вам! Да,, действительно, мы знаем, как превратить профгигиену с приятную spa-процедуру для зубов. Всегда вам рады!
Чистка Air Flow — это отбеливание?
Чистка зубов Air Flow не является отбеливанием. Но она дает отличный эффект: зубы очищаются от пигментированного налёта, эмаль приобретает природный цвет. Заметное осветление происходит из-за качественной очистки зубов, в том числе прокрашенных участков эмали (от кофе, чая, табака, красного вина). Также очищаются труднодоступные межзубные участки – визуально каждый зуб кажется чуть больше. Качественная процедура чистки зубов Air Flow длится в среднем около получаса. После чистки зубов Air Flow проводится полировка эмали, она становится глянцевой, сияющей.
Вам сделали профгигиену полости рта. Что важно знать? Рекомендации наших стоматологов!
| Чистка зубов Air Flow: стоимость | |
|---|---|
| Профессиональная гигиена (включая ремотерапию, контроль навыков гигиены, подбор индивидуальных средств) | 13 300 ₽ |
| Профессиональная гигиена при наличии выраженного зубного налета (включая ремотерапию, контроль навыков гигиены, подбор индивидуальных средств) | 15 500 ₽ |
| Профессиональная гигиена во время ортодонтического лечения на брекетах (включая ремотерапию) при выполнении не реже, чем каждые 2-4 месяца | 7 900 ₽ |
| Профессиональная гигиена после окончания ортодонтического лечения на брекетах (включая ремотерапию, контроль навыков гигиены, подбор индивидуальных средств) | 17 900 ₽ |
Поделиться:
Введение в Apache Airflow
Также по теме Airflow:
Apache Airflow — это продвинутый workflow менеджер и незаменимый инструмент в арсенале современного дата инженера. Если смотреть открытые вакансии на позицию data engineer, то нередко встретишь опыт работы с Airflow как одно из требований к позиции.
Я разработал практический курс по Apache Airflow 2.0, он доступен на платформе StartDataJourney, создана она также мною. Сейчас есть возможность приобрести его с 15% скидкой по промокоду EARLYBIRD, действует до конца апреля 2021 года. Ввести промокод можно на этапе оформления заказа. Приятного обучения — Apache Airflow 2.0: практический курс.
Airflow был разработан в 2014 году в компании Airbnb, автор Maxime Beauchemin. Позже инструмент был передан под опеку в организацию Apache, а в январе 2019 получил статус Top-Level проекта. В этой статье я расскажу про установку, настройку и запуск первого дата пайплайна средствами Apache Airflow. К слову, в 2017 году я уже писал про не менее классный и простой инструмент Luigi от компании Spotify. По своей сути эти два инструмента похожи — оба предназначены для запуска цепочек задач (дата пайплайнов), но есть у них и ряд различий о которых я говорил во время своего выступления на PyCON Russia 2019:
В этой статье я постараюсь рассказать о необходимом минимуме для работы с Airflow. Для начала давайте рассмотрим основные сущности инструмента.
DAG (Directed Acyclic Graph)
DAG — это ориентированный ациклический граф, т.е. граф у которого отсутствуют циклы, но могут быть параллельные пути, выходящие из одного и того же узла. Простыми словами DAG это сущность, объединяющая ваши задачи в единый data pipeline (или цепочку задач), где явно видны зависимости между узлами.
На картинке можно видеть классический DAG, где Task E является конечным в цепочке и зависит от всех задача слева от него.
Operator
Если вы знакомы с инструментом Luigi, то Operator в Airflow это аналог Task в Luigi. Оператор это звено в цепочке задач. Используя оператор разработчик описывает какую задачу необходимо выполнить. В Airflow есть ряд готовых операторов, например:
- PythonOperator — оператор для исполнения python кода
- BashOperator — оператор для запуска bash скриптов/команд
- PostgresOperator — оператор для вызова SQL запросов в PostgreSQL БД
- RedshiftToS3Transfer — оператор для запуска UNLOAD команды из Redshift в S3
- EmailOperator — оператор для отправки электронных писем
Полный список стандартных операторов можно найти в документации Apache Airflow.
DAG является объединяющей сущностью для набора операторов, т.е. если вернуться к картинке выше, то Task A, Task B и т.д. это отдельные операторы.
Важно! Операторы не могут принимать возвращаемые значения от выполнения предыдущих операторов в цепочке (как, например, цепочка из вызовов функций), т.к. могут исполняться в разном адресном пространстве и даже на разных физических машинах.
Sensor
Сенсор это разновидность Operator, его удобно использовать при реализации событийно ориентированных пайплайнов. Из стандартного набора есть, например:
- PythonSensor — ждём, когда функция вернёт
True - S3Sensor — проверяет наличие объекта по ключу в S3-бакете
- RedisPubSubSensor — проверяет наличие сообщения в pub-sub очереди
- RedisKeySensor — проверяет существует ли переданный ключ в Redis хранилище
Это лишь малая часть доступных для использования сенсоров. Чтобы создать свой сенсор, достаточно унаследоваться от BaseSensorOperator и переопределить метод poke.
Hook
Хуки это внешние интерфейсы для работы с различными сервисами: базы данных, внешние API ресурсы, распределенные хранилища типа S3, redis, memcached и т.д. Хуки являются строительными блоками операторов и берут на себя всю логику по взаимодействию с хранилищем конфигов и доступов (о нём ниже). Используя хуки можно забыть про головную боль с хранением секретной информации в коде (пароли к доступам, например).
Установка
Apache Airflow состоит из нескольких частей:
- Веб-приложение с панелью управления, написано на Flask
- Планировщик (Scheduler), в production среде чаще всего используется Celery
- Воркер, выполняющий работу. В production среде также чаще всего встречается конфигурация с Celery.
В качестве базы данных рекомендуется использовать PostgreSQL или MySQL. В этом посте речь пойдёт про установку и настройку Apache Airflow руками, я не буду использовать готовые образы Docker, чтобы наглядно показать как всё запускается изнутри.
Погнали! Создаём новое виртуальное окружение Python, и ставим в него Apache Airflow:
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install apache-airflow
У Airflow много зависимостей в отличие от Luigi, поэтому на экране будет много текста. Вот, например, результат вывода pip freeze:
alembic==1.4.0
apache-airflow==1.10.9
apispec==1.3.3
argcomplete==1.11.1
attrs==19.3.0
Babel==2.8.0
cached-property==1.5.1
cattrs==0.9.0
certifi==2019.11.28
chardet==3.0.4
Click==7.0
colorama==0.4.3
colorlog==4.0.2
configparser==3.5.3
croniter==0.3.31
defusedxml==0.6.0
dill==0.3.1.1
docutils==0.16
Flask==1.1.1
Flask-Admin==1.5.4
Flask-AppBuilder==2.2.2
Flask-Babel==0.12.2
Flask-Caching==1.3.3
Flask-JWT-Extended==3.24.1
Flask-Login==0.4.1
Flask-OpenID==1.2.5
Flask-SQLAlchemy==2.4.1
flask-swagger==0.2.13
Flask-WTF==0.14.3
funcsigs==1.0.2
future==0.16.0
graphviz==0.13.2
gunicorn==19.10.0
idna==2.8
importlib-metadata==1.5.0
iso8601==0.1.12
itsdangerous==1.1.0
Jinja2==2.10.3
json-merge-patch==0.2
jsonschema==3.2.0
lazy-object-proxy==1.4.3
lockfile==0.12.2
Mako==1.1.1
Markdown==2.6.11
MarkupSafe==1.1.1
marshmallow==2.19.5
marshmallow-enum==1.5.1
marshmallow-sqlalchemy==0.22.2
numpy==1.18.1
pandas==0.25.3
pendulum==1.4.4
pkg-resources==0.0.0
prison==0.1.2
psutil==5.6.7
Pygments==2.5.2
PyJWT==1.7.1
pyrsistent==0.15.7
python-daemon==2.1.2
python-dateutil==2.8.1
python-editor==1.0.4
python3-openid==3.1.0
pytz==2019.3
pytzdata==2019.3
PyYAML==5.3
requests==2.22.0
setproctitle==1.1.10
six==1.14.0
SQLAlchemy==1.3.13
SQLAlchemy-JSONField==0.9.0
SQLAlchemy-Utils==0.36.1
tabulate==0.8.6
tenacity==4.12.0
termcolor==1.1.0
text-unidecode==1.2
thrift==0.13.0
typing==3.7.4.1
typing-extensions==3.7.4.1
tzlocal==1.5.1
unicodecsv==0.14.1
urllib3==1.25.8
Werkzeug==0.16.1
WTForms==2.2.1
zipp==2.2.0
zope.deprecation==4.4.0
После установки пакета apache-airflow, в виртуальном окружении будет доступна команда airflow. Запустите её без параметров, чтобы увидеть список доступных команд.
Apache Airflow свои настройки хранит в файле airflow.cfg, который по умолчанию будет создан в домашней директории юзера по пути ~/airflow/airflow.cfg. Путь можно изменить, присвоив переменной окружения новое значение:
$ export AIRFLOW_HOME=~/airflow/
Далее выполняем инициализацию для базы данных.
$ airflow initdb
Эта команда накатит все миграции, по умолчанию в качестве базы данных Airflow использует SQLite. Для демонстрационных возможностей это нормально, но в реальном бою лучше всё же переключиться на MySQL или PostgreSQL. Давайте делать всё по-взрослому. Я буду использовать Postgres, поэтому если он у вас до сих пор не стоит, то самое время установить PostgreSQL.
Создаю базу данных и пользователя к ней для Airflow:
postgres=# create database airflow_metadata;
CREATE DATABASE
postgres=# CREATE USER airflow WITH password 'airflow';
CREATE ROLE
postgres=# grant all privileges on database airflow_metadata to airflow;
GRANT
А теперь открываем airflow.cfg и правим значение параметра sql_alchemy_conn на postgresql+psycopg2://airflow:airflow@localhost/airflow_metadata и load_examples = False. Последний параметр отвечает за загрузку примеров с бесполезными DAGами, они нам не нужны.
В качестве python-драйвера для PostgreSQL я использую psycopg2, поэтому её необходимо поставить в окружение:
$ pip install psycopg2==2.8.4
Инициализируем новую базу данных:
$ airflow initdb
Airflow Executors
Хочу немножко отвлечься от запуска Airflow и рассказать про очень важную концепцию — Executors. Как понятно из названия, Executors отвечают за исполнение задач. В Airflow есть несколько видов исполнителей:
- SequentialExecutor
- LocalExecutor
- CeleryExecutor
- DaskExecutor
- KubernetesExecutor
В боевой среде чаще всего встречается CeleryExecutor, который, как можно догадаться, использует Celery. Но обо всём по порядку.
SequentialExecutor
Этот исполнитель установлен в качестве значения по умолчанию в airflow.cfg у параметра executor и представляет из себя простой вид воркера, который не умеет запускать параллельные задачи. Как можно догадаться, в конкретный момент времени выполняться может только одна единственная задача. Этот вид исполнителя используют в ознакомительных целях, для продуктивной среды он категорически не подходит.
LocalExecutor
Этот вид исполнителя даёт максимальные ощущения продуктивной среды в тестовом окружении (или окружении разработки). Он умеет выполнять задачи параллельно (например, исполнять несколько DAGов одновременно) путём порождения дочерних процессов, но всё же не совсем предназначен для продакшена ввиду ряда проблем:
- Ограничение при масштабировании (возможно эта проблема не будет актуальна для вас), исполнитель этого типа ограничен ресурсами машины на котором он запущен
- Отсутствие отказоустойчивости. Если машина с этим типом воркера падает, то задачи перестают исполнять до момента её возвращения в строй.
При небольшом количестве задач всё же можно использовать LocalExecutor, т.к. это проще, быстрее и не требует настройки дополнительных сервисов.
CeleryExecutor
Наиболее популярный вид исполнения задач. Под капотом использует всю магию таск-менеджера Celery, а соответственно тянет за собой все зависимости этого инструмента. Чтобы использовать CeleryExecutor необходимо дополнительно настроить брокер сообщений. Чаще всего используют либо Redis либо RabbitMQ. Преимущества этого вида в том, что его легко масштабировать — поднял новую машину с воркером, и он готов выполнять требуемую работу, а также в отказоустойчивости. В случае падения одного из воркеров его работа будет передана любому из живых.
DaskExecutor
Очень похож на CeleryExecutor, но только вместо Celery использует инструмент Dask, в частности dask-distributed.
KubernetesExecutor
Относительно новый вид исполнения задач на кластере Kubernetes. Задачи исполняются как новые pod инстансы. В связи с развитием контейнеров и их повсеместным использованием, данный вид исполнения может быть интересен широкому кругу людей. Но у него есть минус — если у вас нет Kubernetes кластера, то настроить его будет непростым упражнением.
Так к чему я начал разговор про Executors. В стандартной конфигурации Airflow предлагает нам использовать SequentialExecutor, но мы ведь стараемся подражать продуктивной среде, поэтому будем использовать LocalExecutor. В airflow.cfg поменяйте значение параметра executor на LocalExecutor.
Запускаем веб-приложение на 8080 порту:
$ airflow webserver -p 8080
Если всё настроено правильно, то переход по адресу localhost:8080 должен показать страницу как на скриншоте:
Поздравляю! Мы настроили и запустили Apache Airflow. На странице можно заметить сообщение:
The scheduler does not appear to be running. The DAGs list may not update, and new tasks will not be scheduled.
Сообщение указывает на то, что не запущен планировщик Airflow (scheduler). Он отвечает за DAG discovery (обнаружение новых DAG), а также за планирование их запуска. Запустить планировщик можно командой:
$ airflow scheduler
Для того, чтобы не переключаться между разными окнами терминалов, я люблю использовать менеджер терминалов tmux.
Итак, база настроена, веб-приложение и планировщик запущены. Нам остаётся только написать наш первый data pipeline и почувствовать себя в шкуре крутого дата инженера.
Строим data pipeline на Apache Airflow
В файле настроек airflow.cfg есть параметр dags_folder, он указывает на путь, где лежат файлы с DAGами. Это путь $AIRFLOW_HOME/dags. Именно туда мы положим наш код с задачами.
Какие задачи будет выполнять пайплайн? Я решил для демонстрации взять пример с датасетом Titanic о котором писал в статье про pandas. Суть в том, что сначала необходимо будет скачать датасет, следующим шагом будет этап создания сводной таблицы: сгруппируем пассажиров по полу и пассажирскому классу, чтобы узнать количество людей в каждом классе. Результатом будет новый csv-файл со сводной таблицей.
Вот так выглядит DAG:
А вот код всего DAGа, включая 2 оператора:
import os
import datetime as dt
import requests
import pandas as pd
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
args = {
'owner': 'airflow',
'start_date': dt.datetime(2020, 2, 11),
'retries': 1,
'retry_delay': dt.timedelta(minutes=1),
'depends_on_past': False,
}
FILENAME = os.path.join(os.path.expanduser('~'), 'titanic.csv')
def download_titanic_dataset():
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
response = requests.get(url, stream=True)
response.raise_for_status()
with open(FILENAME, 'w', encoding='utf-8') as f:
for chunk in response.iter_lines():
f.write('{}\\n'.format(chunk.decode('utf-8')))
def pivot_dataset():
titanic_df = pd.read_csv(FILENAME)
pvt = titanic_df.pivot_table(
index=['Sex'], columns=['Pclass'], values='Name', aggfunc='count'
)
df = pvt.reset_index()
df.to_csv(os.path.join(os.path.expanduser('~'), 'titanic_pivot.csv'))
with DAG(dag_id='titanic_pivot', default_args=args, schedule_interval=None) as dag:
create_titanic_dataset = PythonOperator(
task_id='download_titanic_dataset',
python_callable=download_titanic_dataset,
dag=dag
)
pivot_titanic_dataset = PythonOperator(
task_id='pivot_dataset',
python_callable=pivot_dataset,
dag=dag
)
create_titanic_dataset >> pivot_titanic_dataset
В DAGе у нас используются 2 PythonOperator. Обратите внимание, что они принимают функцию, которую необходимы выполнить. В первом случае это download_titanic_dataset, которая скачивает датасет из сети, во втором случае это pivot_dataset, которая сохраняет сводную таблицу из исходного файла (сохраненного предыдущей функцией).
Стоит обратить внимание на объект DAG и то как описаны зависимости между двумя операторами. В Airflow допустимы конструкции >> и <<, а также методы .set_upstream и .set_downstream. Т.е. код:
create_titanic_dataset >> pivot_titanic_datasetМожно заменить на:
pivot_titanic_dataset.set_upstream(create_titanic_dataset)
# или
pivot_titanic_dataset << create_titanic_datasetЭто означает, что выполнение оператора pivot_titanic_dataset зависит от выполнения оператора create_titanic_dataset.
На уровне объекта DAG задаются настройки, например:
- Время начала выполнения пайплайна (
start_date) - Периодичность запуска (
schedule_interval) - Информация о владельце DAG (
owner) - Количество повторений в случае неудач (
retries) - Пауза между повторами (
retry_delay)
Параметров в разы больше. Более подробно как всегда можно прочитать в доках.
Итак, сохраняем в файл код и помещаем его по пути $AIRFLOW_HOME/dags. Для того, чтобы DAGи отображались в интерфейсе Airflow необходимо запустить планировщик:
$ airflow schedulerЕсли всё сделано верно, то в списке появится наш DAG:
Его можно активировать, переключив с Off на On и попробовать запустить (Trigger Dag).
Заключение
Эта статья лишь небольшое введение в Apache Airflow. Я не раскрыл и 20% того, что умеет инструмент, но и такой задачи себе не ставил. Лучшим способом изучить Apache Airflow является работа с ним. Пробуйте, экспериментируйте, чтобы понять подходит он под ваши задачи или нет.
Ссылка на репозиторий с примерами: https://github.com/adilkhash/apache-airflow-intro
💌 Присоединяйтесь к рассылке
Понравился контент? Пожалуйста, подпишись на рассылку.
Чистка и осветление зубов AirFlow
Эффективная чистка и осветление эмали зубов
Современная стоматология предлагает широкий спектр гигиенических и косметических процедур. Одной из наиболее востребованных среди них является профессиональная чистка Air Flow. Она эффективно удалять зубной налет со всех зубных поверхностей, в том числе на труднодоступных участках. Чистка методом Air Flow осветляет эмаль примерно на 2-3 тона, делает зубы белоснежными и красивыми.
Что такое Air Flow?
Гигиеническая чистка зубов Air Flow — быстрый и безопасный способ удалить зубной налет и вернуть зубам их естественный (природный) цвет. В начале процедуры десны пациента накрываются специальным защитным материалом. Затем, с помощью аппарата Air Flow, поверхность зубов под большим давлением обрабатывается аэрозольной струей, которая содержит воду, воздух и особый порошок на основе бикарбоната натрия (соды). В заключение процедуры проводят фторирование зубов, чтобы восполнить недостаток нужных веществ в эмали и дентине и снизить повышенную чувствительность зубов после очищения.
Показания и противопоказания
Чистка зубов Air Flow показана для удаления мягкого налета, который образуется на зубах от употребления красящих продуктов, курения. Кроме того, врачи рекомендуют чистку Air Flow после снятия брекетов, а также перед любыми стоматологическими манипуляциями, будь то лечение кариеса, фторирование или отбеливание.
Процедура абсолютно безопасна и все же имеет некоторые противопоказания и ограничения. Решение о проведении процедуры должен принимать врач-стоматолог на основании осмотра пациента и выяснении общего состояния его здоровья. Чистку Air Flow не рекомендуют проводить детям, женщинам в период беременности и лактации, пациентам, страдающим астмой или хроническим бронхитом. Порошок, используемый при чистке, обладает лимонным вкусом, поэтому Air Flow противопоказана при непереносимости цитрусовых.
Чистка методом AirFlow или отбеливание зубов?
Ответ на этот вопрос зависит от того, к какому результату стремится пациент. Если он доволен природным оттенком своих зубов, то чистка и осветление зубов с применением пескоструйной технологии Air Flow раз в полгода — это то, что надо.
Для тех, кто недоволен натуральным оттенком своих зубов, чистка Air Flow может стать отличным стартом перед отбеливанием, таким как ZOOM! 4. Профессиональное отбеливание зубов системой ZOOM! 4 удаляет не только поверхностные, но и внутренние пигментации, и осветляет зубы на 8–12 тонов за 1 сеанс.
Как часто можно проводить данную процедуру?
Для поддержания естественного оттенка зубов и соблюдения гигиены полости рта, стоматологи рекомендуют проводить чистку зубов Air Flow 2 раза в год.
Процедура отбеливания Air Flow: особенности, показания и противопоказания
Отбеливание зубов Air Flow – белые и чистые зубы после первого визита
Красивая улыбка – неотъемлемый атрибут имиджа современного человека. Она моментально располагает окружающих и значительно повышает шансы на успех. Но чтобы улыбка была белоснежной и привлекательной, о ней необходимо заботиться. Даже правильный и регулярный уход за полостью рта не способен предотвратить образование налёта в труднодоступных местах, что со временем может привести к кариесу, пульпиту, периодонтиту и т. д. Именно поэтому современная стоматология неустанно разрабатывает инновационные методы эффективной чистки зубов.
Одним из наиболее удачных, доступных и эффективных способов является воздействие ультразвуком. Это профессиональная гигиеническая процедура, известная как отбеливание зубов Air Flow. Предлагаем воспользоваться такой услугой в одной из стоматологических клиник «НоваДент».
Возможности процедуры отбеливания зубов Air Flow
Отбеливание зубов системой Air Flow позволяет осветлить эмаль до природного оттенка. Процедура снимает:
-
зубной камень и пигментацию;
-
следы кофе и чая;
-
зубной налёт;
-
пигментацию курильщика и т. д.
Чистка Air Flow также позволяет устранить источник неприятного запаха из ротовой полости – бактерии. Она помогает не только преобразить зубы, но и подготовить их к дальнейшему лечению и диагностике.
Особенности проведения
Отбеливание Air Flow проводится с помощью специального пескоструйного аппарата. В нём находится лечебный состав, который представляет собой мелкодисперсную смесь воды и абразивного вещества. Такой раствор под давлением наносится на поверхность каждого зуба, очищает и отбеливает его. При этом специалист воздействует не только на фронтальную часть эмали, но и на труднодоступные места.
Твёрдые частицы в лечебном растворе характеризуются сферической формой. Поэтому методика позволяет получить не абразивный, а полирующий эффект.
Инновационный подход к гигиене и чистке полости рта
Отбеливание системой Air Flow является для пациента совершенно безболезненной. Такая процедура позволяет избежать применения дорогостоящих и интенсивных методик. Чистка Air Flow бережно и мягко преображает улыбку и при этом:
-
не травмирует дёсны;
-
проходит с максимальным комфортом;
-
не повреждает зубную эмаль.
Процедура позволяет получить не только очищающий, но и отбеливающий эффект. Как правило, по окончании сеанса зубы становятся светлее на 1–2 тона. Ещё одним немаловажным преимуществом отбеливания зубов Air Flow является низкая цена услуги. Стоимость чистки выгоднее множества других альтернативных методик, но позволяет достичь желаемых результатов.
Противопоказания
Отбеливание можно беспрепятственно проводить при наличии у пациента виниров, коронок и люминиров. Так как эти элементы также легко поддаются чистке. Противопоказанием к проведению процедуры является:
Также не рекомендуется проводить чистку Air Flow женщинам в период беременности и лактации.
Доверьте красоту своей улыбки профессионалам
В Москве и Московской области на процедуру отбеливания зубов системой Air Flow приглашает сеть стоматологических клиник «НоваДент». Двери любого из 15 наших учреждений открыты для всех желающих обрести улыбку своей мечты. Для вас:
-
умеренные цены;
-
отсутствие очередей;
-
вежливый персонал;
-
передовое оборудование;
-
новейшие технологии;
-
приятная атмосфера и комфортная обстановка.
Наши доктора выполняют процедуру максимально внимательно, бережно и аккуратно. По завершении чистки проводится фторирование зубов для их дополнительного укрепления и снижения чувствительности эмали.
AirFlow отчистка зубов
Технология Air Flow разработана довольно давно. Оборудование для проведения чистки зубов по этой технологие производит множество фирм. Семейный стоматологический центр «Диал-Дент» использует в своей работе только самое современное оборудование надежных производителей.
Технология профессиональной чистки зубов, называемая Air Flow, предназначена для идеальной отчистки зубов от поверхностных пигментаций (налет от чая, кофе, сигарет и др.) и мягкого зубного налета. Эта технология позволяет отчистить труднодоступные места, например межзубные промежутки. Твердые зубные отложения (зубные камни) не поддаются Air Flow, для них необходимо применять другие технологии.
Принцип действия технологии
Air Flow:- Специальное сопло гигиенист подводит вплотную к зубам пациента.
- Из сопла под давлением поступает воздушно-водяная смесь, содержащая специальный порошок. Это мелкодисперсный неабразивный порошок на основе бикарбоната натрия, имеющий приятный вкус. Ударяясь о поверхность зуба, порошок снимает налет.
- С помощью специального стоматологического пылесоса, с другой стороны обрабатываемого зуба, собирается отработанные вода, порошок и частички налета прямо во рту пациента, предотвращая их разлетание.
Air Flow это не отбеливание, как часто упоминается в рекламе. При отбеливании изменяется собственный цвет зубов, а при профессиональной чистке зубов по технологии Air Flow изменения собственного цвета не происходит, возвращается истинный цвет зубов.
Показания к применению Air Flow:
- Отчистка брекетов
- Отчистка головок имплантатов
- Отчистка зубов для определения цвета перед проведением реставраций или др.
- Отчистка перед фторирующей терапией (для укрепления эмали)
- Отчистка перед отбеливанием
- Гигиеническая подготовка перед хирургическим вмешательством (в том числе перед удалением зубов) или комплексным стоматологическим лечением
- Гигиеническая подготовка перед установкой брекетов
Противопоказания для применения Air Flow:
- Хронический бронхит или астма в анамнезе пациента – может спровоцировать приступ затрудненного дыхания.
- Нахождение пациента на бессолевой диете – порошок содержит соль и возможно ее попадание в организм пациента.
- Известная пациенту непереносимость цитрусового вкуса (только для чистящего порошка с цитрусовым вкусом).
Как проходит процедура отчистки по технологии Air Flow:
- Губы пациента смазываются вазелином для предупреждения высыхания и растрескивания.
- На пациента обязательно надевают защитные очки и шапочку.
- Проводится индикация зубного налета.
- Гигиенист направляет наконечник, из которого распыляется состав, под углом 30-60 градусов к эмали зуба. Состав не распыляется на десну или открытые участки дентина! Одновременно пылесосом удаляются остатки порошка и вода.
- Каждый зуб очищается со всех сторон.
Семейный стоматологический центр «Диал-Дент» предлагает методику идеальной отчистки зубов:
- Зубной камень снимается ультразвуком (при необходимости).
- Зубы отчищаются с применением технологии Air Flow.
- Проводится дополнительная отчистка профессиональными щетками и пастами.
- С согласия пациента наносится специальное покрытие на зубы, которое защищает и укрепляет эмаль путем выделения фтора.
До снятия зубного камня и налета | После снятия зубного камня и налета |
Рекомендации пациентам, прошедшим
отчистку Air Flow:Нельзя курить, пить чай, кофе и употреблять другие продукты, которые могут вызвать окрашивание эмали, в первые 2 – 3 часа после проведения процедуры.
Это объясняется тем, что при прохождении отчистки Air Flow теряется органическая пленка, покрывающая зуб – кутикула. Она восстанавливается из слюны в течение 2 – 3 часов.
В Семейном стоматологическом центре «Диал-Дент» используется аппарат AIRFLOW prophylaxis master фирмы EMS (Швейцария).
Запись на консультацию по телефону +7-499-110-18-04 или через форму на сайте. Задать вопросы по профессиональной чистке, лечению и протезированию зубов можно главному врачу клиники Цукору Сергею Владимировичу в Facebook.
7 достоинств и 5 недостатков Apache AirFlow | by Nick Komissarenko
Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования.
Чем хорош Apache AirFlow: главные плюсыПроанализировав прикладное назначение и функциональные возможности Apache Airflow, можно сделать выводы, что главными положительными качествами этого фреймворка для разработки, планирования и мониторинга пакетных процессов работы с большими данными являются следующие:
· небольшой, но полноценный инструментарий создания процессов обработки данных и управления ими — 3 вида операторов (сенсоры, обработчики и трансферы), расписание запусков для каждой цепочки задач, логгирование сбоев [1];
· графический веб-интерфейс для создания конвейеров данных (data pipeline), который обеспечивает относительно низкий порог входа в технологию, позволяя работать с AirFlow не только инженеру данных (Data Engineer), но и аналитику, разработчику, администратору и DevOps-инженеру. Пользователь может наглядно отслеживать жизненный цикл данных в цепочках связанных задач, представленных в виде направленного ациклического графа (Directed Acyclic Graph) [2].
· Расширяемый REST API, который относительно легко интегрировать AirFlow в существующий ИТ-ландшафт корпоративной инфраструктуры и гибко настраивать конвейеры данных, например, передавать POST-параметры в DAG [3].
· Программный код на Python, который считается относительно простым языком для освоения и профессиональным стандартом де-факто для современного специалиста в области Big Data и Data Science: инженера, аналитика, разработчика больших данных и специалиста по машинному обучению [4].
· Интеграция со множеством источников и сервисов — базы данных (MySQL, PostgreSQL, DynamoDB, Hive), Big Data хранилища (HDFS, Amazon S3) и облачные платформ (Google Cloud Platform, Amazon Web Services, Microsoft Azure) [2].
· Наличие собственного репозитория метаданных на базе библиотеки SqlAlchemy, где хранятся состояния задач, DAG’ов, глобальные переменные и пр. [5].
· Масштабируемость за счет модульной архитектуры и очереди сообщений для неограниченного числа DAG’ов [5].
Пример кода ETL-задач на языке Python в AirFlow и графическое отображение цепочки задач в виде DAG
Cложности с ЭйрФлоу: ключевые ограничения и способы их обходаОбратной стороной вышеотмеченных достоинств являются следующие недостатки:
· наличие неявных зависимостей при установке, например, дополнительные пакеты типа greenlet, gevent, cryptography и пр. усложняют быстрое конфигурирование этого фреймворка [5];
· большие накладные расходы (временная задержка 5–10 секунд) на постановку DAG’ов в очередь и приоритезицию задач при запуске [4];
· необходимость наличия свободного слота в пуле задач и рабочего экземпляра планировщика. Например, Data Engineer’ы компании Mail.ru выделяют сенсоры (операторы для извлечения данных, операция Extract в ETL-процессе) в отдельный пул, чтобы таким образом контролировать количество и приоретизировать их, сокращая общую временную задержку (latency) [4];
· пост-фактум оповещения о сбоях в конвейере данных, в частности, в интерфейсе Airflow логи появятся только после того, как задание, к примеру, Spark-job, отработано. Поэтому следить в режиме онлайн, как выполняется data pipeline, приходится из других мест, например, веб-интерфейса YARN. Именно такое решение по работе с Apache Spark и Airflow было принято в онлайн-кинотеатре IVI [3].
· Разделение по операторам — каждый оператор Airflow исполняется в своем python-интерпретаторе. Файл, который создается для определения DAG — это не просто скрипт, который обрабатывает какие-то данные, а объект. В процессе выполнения задачи DAG не могут пересекаться, так как они выполняются на разных объектах и в разное время. При этом на практике иногда возникает потребности, чтобы несколько операторов Airflow могли выполняться в одном Spark-контексте над общим пространством dataframe’ов. Реализовать это можно с помощью Apache Livy — REST-API сервиса для взаимодействия с кластером Spark, как сделано в компании АльфаСтрахование [6].
Пример Big Data системы на основе Apache Airflow, Livy, PostreSQL и веб-сервисов Amazon
Как применять на практике преимущества Apache AirFlow и обойти его недостатки для эффективного управления большими данными, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
AIRF: Apache AirFlow
Смотреть расписание занятий
Зарегистрироваться на курс
Источники
1. https://habr.com/ru/company/newprolab/blog/358530/
2. https://airflow.apache.org/
3. https://habr.com/ru/company/ivi/blog/456630/
4. https://habr.com/ru/company/mailru/blog/339392/
5. https://ru.bmstu.wiki/Apache_Airflow
6. https://habr.com/ru/company/alfastrah/blog/466017/
ДокументацияApache Airflow — Документация Airflow
Airflow — это платформа для программного создания, планирования и мониторинга рабочие процессы.
Используйте Airflow для создания рабочих процессов как направленных ациклических графов (DAG) задач. Планировщик Airflow выполняет ваши задачи для множества рабочих, в то время как следуя указанным зависимостям. Богатые утилиты командной строки делают Выполнение сложных операций на DAG несложно. Богатый пользовательский интерфейс позволяет легко визуализировать трубопроводы, работающие в производстве, отслеживать прогресс и при необходимости устранять неполадки.
Когда рабочие процессы определены как код, они становятся более удобными в обслуживании, версионный, тестируемый и совместный.
Принципы
Dynamic : Конвейеры воздушного потока конфигурируются как код (Python), что позволяет создавать динамические конвейеры. Это позволяет писать код, который динамически создает экземпляры конвейеров.
Extensible : легко определяйте собственных операторов, исполнителей и расширяйте библиотеку, чтобы она соответствовала уровню абстракции, подходящему для вашей среды.
Elegant : Трубопроводы воздушного потока компактны и понятны. Параметризация ваших скриптов встроена в ядро Airflow с использованием мощного движка шаблонов Jinja .
Scalable : Airflow имеет модульную архитектуру и использует очередь сообщений для организации произвольного количества рабочих процессов. Воздушный поток готов к бесконечному масштабированию.
За горизонтом
Airflow — это не для потоковой передачи данных.Задачи не перемещают данные из одна в другую (хотя задачи могут обмениваться метаданными!). Воздушный поток нет в Spark Streaming или Storm space, это больше похоже на Oozie или Азкабан.
Ожидается, что рабочие процессы будут в основном статичными или медленно меняющимися. Ты можешь думать структуры задач в вашем рабочем процессе, как немного более динамичный чем структура базы данных. Ожидается, что рабочие процессы воздушного потока будут выглядеть аналогично от прогона к следующему, это дает ясность в отношении единица работы и преемственность.
Apache Airflow для новичков | Apache Airflow
Apache Airflow — это платформа для программного создания, планирования и мониторинга рабочих процессов. Рабочий процесс — это последовательность задач, которая обрабатывает набор данных. Вы можете думать о рабочем процессе как о путь, который описывает, как задачи переходят от отмены к выполнению. С другой стороны, планирование — это процесс планирования, контроля и оптимизации, когда должна быть выполнена конкретная задача.
Рабочий процесс разработки в Apache Airflow.
Airflow упрощает создание рабочих процессов с использованием скриптов Python. Направленный ациклический граф (DAG) представляет рабочий процесс в Airflow. Это набор задач таким образом, чтобы показать каждую задачу отношения и зависимости. Вы можете иметь столько DAG, сколько хотите, и Airflow выполнит их в соответствии с отношениями и зависимостями задачи. Если задача B зависит от успешного выполнение другой задачи A, это означает, что Airflow будет запускать задачу A и запускать задачу B только после задачи A. Эту зависимость очень легко выразить в Airflow.Например, приведенный выше сценарий выражается как
. задача_A >> задача_B
Также эквивалент
task_A.set_downstream (task_B)
Это помогает Airflow знать, что ему нужно выполнить задачу A перед задачей B. Задачи могут быть гораздо более сложными. отношения друг к другу, чем указано выше, и Airflow выясняет, как и когда выполнять следующие задачи. их отношения и зависимости.
Прежде чем мы обсудим архитектуру Airflow, которая обеспечивает планирование, выполнение и мониторинг рабочий процесс — простая вещь, давайте обсудим среду Breeze.
Ветерок
Среда Breeze — это среда разработки для Airflow, в которой вы можете запускать тесты, создавать образы и т. Д.
создавать документацию и многое другое. Есть отличные
документация и видео по среде Breeze.
Пожалуйста, проверьте их. Чтобы войти в среду Breeze, выполните сценарий ./breeze . Вы можете запустить все
упомянутые здесь команды в среде Breeze.
Планировщик
Планировщик — это компонент, который отслеживает группы DAG и запускает те задачи, зависимости которых имеют встречались.Он следит за папкой DAG, проверяет задачи в каждой DAG и запускает их, как только они готовы. Он выполняет это, порождая процесс, который запускается периодически (каждую минуту или около того). чтение базы данных метаданных, чтобы проверить статус каждой задачи и решить, что нужно сделать. База данных метаданных — это место, где записывается статус всех задач. Статус может быть одним из запущенных, успех, неудача и т. д.
Задача считается готовой, когда выполнены ее зависимости. Зависимости включают все данные
необходимо для выполнения задачи.Следует отметить, что планировщик не запускает ваши задачи до тех пор, пока
период, который он охватывает, закончился. Если schedule_interval задачи @daily , планировщик запускает задачу.
в конце дня, а не в начале. Это необходимо для того, чтобы данные, необходимые для выполнения задач
готовы. Также можно запускать задачи вручную в пользовательском интерфейсе.
В среде Breeze планировщик запускается командой планировщик воздушного потока .Оно использует
настроенная производственная среда. Конфигурацию можно указать в airflow.cfg
Исполнитель
Исполнители несут ответственность за выполнение задач. Они работают с планировщиком, чтобы получить информацию о какие ресурсы необходимы для выполнения задачи, когда задача поставлена в очередь.
По умолчанию Airflow использует SequentialExecutor. Однако этот исполнитель ограничен, и это единственный исполнитель, который можно использовать с SQLite.
Есть много других исполнителей, разница заключается в имеющихся у них ресурсах и в том, как они решают их использовать.Доступные исполнители являются:
- Последовательный исполнитель
- Исполнитель отладки
- Местный исполнитель
- Исполнитель Dask
- Палач сельдерея
- Исполнитель Kubernetes
- Масштабирование с помощью Mesos (внесено сообществом)
CeleryExecutor — лучший исполнитель по сравнению с SequentialExecutor. CeleryExecutor использует несколько рабочих для выполнения работы распределенным образом. Если рабочий узел когда-либо выходит из строя, CeleryExecutor назначает его задача на другой рабочий узел.Это обеспечивает высокую доступность.
CeleryExecutor тесно взаимодействует с планировщиком, который добавляет сообщение в очередь, и брокером Celery. который доставляет сообщение работнику Celery для выполнения. Вы можете найти дополнительную информацию о CeleryExecutor и о том, как его настроить на документация
Веб-сервер
Веб-сервер — это веб-интерфейс (UI) для Airflow. Пользовательский интерфейс многофункциональный. Это позволяет легко отслеживать и устранять неполадки в группах DAG и задачах.
Пользовательский интерфейс позволяет выполнять множество действий.Вы можете запускать задачу, следить за выполнением включая продолжительность задачи. Пользовательский интерфейс позволяет просматривать зависимости задачи в представление в виде дерева и графика. Вы можете просматривать журналы задач в пользовательском интерфейсе.
Веб-интерфейс запускается командой airflow webserver в среде Breeze.
Бэкэнд
По умолчанию Airflow использует серверную часть SQLite для хранения информации о конфигурации, состояний DAG, и много другой полезной информации. Это не должно использоваться в производстве, поскольку SQLite может вызвать данные потеря.
Вы можете использовать PostgreSQL или MySQL как серверную часть для воздушного потока. Легко перейти на PostgreSQL или MySQL.
Команда ./breeze --backend mysql выбирает MySQL в качестве серверной части при запуске среды breeze.
Операторы
Операторы определяют, что делает задача. Airflow имеет множество встроенных операторов. Каждый оператор выполняет конкретную задачу. Есть BashOperator, который выполняет команду bash, PythonOperator, который вызывает функцию Python, AwsBatchOperator, которая выполняет задание в AWS Batch, и многое другое.
Датчики
Датчикиможно описать как специальные операторы, которые используются для отслеживания длительной задачи. Как и в случае с операторами, в Airflow есть множество предопределенных датчиков. Сюда входит
- AthenaSensor: запрашивает состояние запроса до тех пор, пока он не достигнет состояния отказа или состояния успеха.
- AzureCosmosDocumentSensor: проверяет наличие документа, соответствующего заданному запросу в CosmosDB
- GoogleCloudStorageObjectSensor: проверяет наличие файла в Google Cloud Storage
Список большинства доступных датчиков можно найти в этом модуле
способствует воздушному потоку
Airflow — проект с открытым исходным кодом, каждый может внести свой вклад.Начать работу легко, спасибо к отличной документации о том, как начать работу.
Я присоединился к сообществу около 12 недель назад через информационную программу и выполнено около 40 сбн.
Это был потрясающий опыт! Спасибо моим наставникам Яреку и Кахил и члены сообщества, особенно Камил и Томеку за всю их поддержку. Я благодарен!
Большое спасибо, Лия Э. Коул, за ваши прекрасные отзывы.
GitHub — apache / воздушный поток: Apache Airflow
Apache Airflow (или просто Airflow) — это платформа для программного создания, планирования и мониторинга рабочих процессов.
Когда рабочие процессы определены как код, они становятся более удобными для сопровождения, версионирования, тестирования и совместной работы.
Используйте Airflow для создания рабочих процессов в виде ориентированных ациклических графов (DAG) задач. Планировщик Airflow выполняет ваши задачи на массиве работников, следуя указанным зависимостям. Богатые служебные программы командной строки упрощают выполнение сложных операций на DAG. Богатый пользовательский интерфейс позволяет легко визуализировать конвейеры, работающие в производственной среде, отслеживать прогресс и при необходимости устранять неполадки.
Содержание
Проектный фокус
Airflow лучше всего работает с рабочими процессами, которые в основном статичны и медленно меняются. Когда структура DAG одинакова от одного запуска к другому, это дает ясность в отношении единицы работы и непрерывности. Другие подобные проекты включают Луиджи, Узи и Азкабан.
Airflow обычно используется для обработки данных, но придерживается мнения, что задачи в идеале должны быть идемпотентными (т. Е. Результаты задачи будут одинаковыми и не будут создавать дублирующиеся данные в целевой системе) и не должны передавать большие объемы данных. от одной задачи к другой (хотя задачи могут передавать метаданные с помощью функции Airflow Xcom).Для больших объемов задач с большим объемом данных рекомендуется делегировать внешние службы, которые специализируются на этом типе работы.
Airflow не является потоковым решением, но его часто используют для обработки данных в реальном времени, извлекая данные из потоков в пакетном режиме.
Принципы
- Динамический : конвейеры воздушного потока конфигурируются как код (Python), что позволяет создавать динамические конвейеры. Это позволяет писать код, который динамически создает экземпляры конвейеров.
- Extensible : легко определяйте собственных операторов, исполнителей и расширяйте библиотеку, чтобы она соответствовала уровню абстракции, подходящему для вашей среды.
- Elegant : Воздушные трубопроводы компактны и понятны. Параметризация ваших скриптов встроена в ядро Airflow с использованием мощного движка шаблонов Jinja .
- Scalable : Airflow имеет модульную архитектуру и использует очередь сообщений для организации произвольного количества рабочих процессов.
Жизненный цикл версии
Жизненный цикл версии Apache Airflow:
| Версия | Текущий патч / минор | Государство | Первая версия | Ограниченная поддержка | EOL / прекращено |
|---|---|---|---|---|---|
| 2 | 2.1.0 | Поддерживается | 17 декабря 2020 г. | декабрь 2021 г. | TBD |
| 1,10 | 1.10.15 | Ограниченная поддержка | 27 августа 2018 г. | 17 декабря 2020 г. | июнь 2021 г. |
| 1.9 | 1.9.0 | EOL | 3 января 2018 | 27 августа 2018 г. | Август 2018 |
| 1,8 | 1.8.2 | EOL | 19 марта 2017 г. | 3 января 2018 | янв 2018 |
| 1,7 | 1.7.1.2 | EOL | 28 марта 2016 г. | 19 марта 2017 г. | Март 2017 |
Версии с ограниченной поддержкой будут поддерживаться только с безопасностью и исправлением критических ошибок.Версии EOL не получат никаких исправлений и поддержки. Мы всегда рекомендуем всем пользователям запускать последний доступный дополнительный выпуск для любой основной версии, которая используется. Мы настоятельно рекомендуем выполнить обновление до последней основной версии Airflow в ближайшее удобное время и до даты EOL.
Требования
Apache Airflow протестирован с:
| Основная версия (dev) | Стабильная версия (2.0.2) | Предыдущая версия (1.10.15) | |
|---|---|---|---|
| Питон | 3,6, 3,7, 3,8 | 3,6, 3,7, 3,8 | 2,7, 3,5, 3,6, 3,7, 3,8 |
| Кубернетес | 1.20, 1.19, 1.18 | 1.20, 1.19, 1.18 | 1,18, 1,17, 1,16 |
| PostgreSQL | 9,6, 10, 11, 12, 13 | 9,6, 10, 11, 12, 13 | 9,6, 10, 11, 12, 13 |
| MySQL | 5,7, 8 | 5,7, 8 | 5.6, 5,7 |
| SQLite | 3.15.0+ | 3.15.0+ | 3.15.0+ |
| MSSQL (экспериментальный) | 2017,2019 |
Примечание: версии MySQL 5.x не могут или имеют ограничения с запуск нескольких планировщиков — см. документацию по планировщику. MariaDB не тестируется / не рекомендуется.
Примечание: SQLite используется в тестах воздушного потока. Не используйте его в производстве.Мы рекомендуем использование последней стабильной версии SQLite для локальной разработки.
Поддержка версий Python и Kubernetes
Начиная с Airflow 2.0 мы согласились с некоторыми правилами, которым мы следуем для поддержки Python и Kubernetes. Они основаны на официальном расписании выпусков Python и Kubernetes, красиво резюмированном в Руководство разработчика Python и Политика перекоса версий Kubernetes.
Мы прекращаем поддержку версий Python и Kubernetes, когда они достигают EOL. Мы отказываемся от поддержки тех Версии EOL отображаются в основном сразу после даты EOL, и они эффективно удаляются, когда мы выпускаем первый новый НЕЗАВИСИМЫЙ (или ГЛАВНЫЙ, если нет новой МЛАДШЕЙ версии) воздушного потока Например для Python 3.6 это означает, что мы прекращаем поддержку в main сразу после 23.12.2021, а первая ОСНОВНАЯ или МИНИМАЛЬНАЯ версия Airflow, выпущенная после, не будет иметь ее.
По умолчанию используется «самая старая» поддерживаемая версия Python / Kubernetes. «По умолчанию» имеет смысл только в терминах «дымовых тестов» в CI PR, которые запускаются с использованием этой версии по умолчанию и ссылки по умолчанию изображение доступно в DockerHub. В настоящее время
apache / airflow: последниеиapache / airflow: 2.0.2изображений оба Python 3.6 изображений, однако первый МАЛЕНЬКИЙ / БОЛЬШОЙ выпуск выпуска Airflow после 23.12.2021 г. будет становятся изображениями Python 3.7.Мы поддерживаем новую версию Python / Kubernetes в основном после их официального выпуска, как только мы заставить их работать в нашем конвейере CI (что может произойти не сразу из-за зависимостей, догоняющих в основном новые версии Python) мы выпускаем новые изображения / поддержку в Airflow на основе рабочей настройки CI.
Дополнительные примечания к требованиям версии Python
- Для предыдущей версии требуется как минимум Python 3.5,3 при использовании Python 3
Начало работы
Посетите официальный сайт документации Airflow (последний стабильный выпуск ), чтобы получить помощь по установка Airflow, начало работы или прогулка через более полное руководство.
Примечание. Если вам нужна документация для основной ветки (последняя ветка разработки): ее можно найти на s.apache.org/airflow-docs.
Для получения дополнительной информации о предложениях по улучшению воздушного потока (AIP) посетите Вики-сайт Airflow.
Официальные образы Docker (контейнеров) для Apache Airflow описаны в IMAGES.rst.
Установка из PyPI
Мы публикуем Apache Airflow как пакет apache-airflow в PyPI. Однако установка может быть сложной.
потому что Airflow — это своего рода библиотека и приложение. Библиотеки обычно держат свои зависимости открытыми и
приложения обычно закрепляют их, но мы не должны делать ни то, ни другое одновременно. Мы решили оставить
наши зависимости максимально открыты (в файле setup.py ), чтобы пользователи могли устанавливать разные версии библиотек
если нужно. Это означает, что время от времени простой pip install apache-airflow не будет работать или не будет
производят непригодную для использования установку Airflow.
Однако, чтобы иметь возможность повторять установку, мы также сохраняем набор ограничений «заведомо работающие».
файлы в сиротских ветвях constraints-main , constraints-2-0 . Мы сохраняем тех «заведомо работающих»
файлы ограничений отдельно для каждой основной / дополнительной версии Python.Вы можете использовать их как файлы ограничений при установке Airflow из PyPI. Обратите внимание, что вы должны указать
правильный тег / версия / ветка Airflow и версии Python в URL-адресе.
- Установка только Airflow:
Примечание. В настоящее время официально поддерживается установка только
pip.
Хотя у них есть некоторые успехи в использовании других инструментов, таких как поэзия или
pip-tools, они не используют тот же рабочий процесс, что и pip — особенно когда дело доходит до ограничения vs.управление требованиями.
Установка через Poetry или pip-tools в настоящее время не поддерживается.
Если вы хотите установить воздушный поток с помощью этих инструментов, вы должны использовать файлы ограничений и преобразовать их в соответствии с форматом и рабочим процессом, который требуется вашему инструменту.
pip install apache-airflow == 2.0.2 \ --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.0.2/constraints-3.7.txt"
- Установка с дополнительными функциями (например postgres, google)
pip install apache-airflow [postgres, google] == 2.0,2 \ --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.0.2/constraints-3.7.txt"
Информацию об установке пакетов провайдера см. провайдеры.
Официальный исходный код
Apache Airflow — это проект Apache Software Foundation (ASF), и наши официальные выпуски исходного кода:
Согласно правилам ASF, выпущенных исходных пакетов должно быть достаточно, чтобы пользователь мог собрать и протестировать релиз при условии, что у них есть доступ к соответствующей платформе и инструментам.
Комфортные пакеты
Есть и другие способы установки и использования Airflow. Это «удобные» методы — они
не «официальные выпуски», как указано в политике выпуска ASF , но они могут использоваться пользователями
которые не хотят разрабатывать программное обеспечение самостоятельно.
Это — в порядке наиболее распространенных способов установки Airflow:
- Выпуски PyPI для установки Airflow с использованием стандартного инструмента
pip - Docker Images для установки воздушного потока через
dockertool, используйте их в Kubernetes, Helm Charts,docker-compose,docker swarmи т. Д.Ты можешь узнать больше об использовании, настройке и расширении изображений в Последние документы и подробности о внутреннем устройстве см. в документе IMAGES.rst. - Теги в GitHub для получения источников проекта git, которые были использованы для генерации официальных исходных пакетов через git
Все эти артефакты не являются официальными выпусками, но они подготовлены с использованием официально выпущенных источников. Некоторые из этих артефактов находятся в стадии разработки или перед выпуском, и они четко обозначены как таковые. следуя политике ASF.
Пользовательский интерфейс
DAG : Обзор всех DAG в вашей среде.
Древовидное представление : Древовидное представление группы доступности базы данных, охватывающей время.
Графическое представление : Визуализация зависимостей группы доступности базы данных и их текущего состояния для определенного запуска.
Длительность задачи : Общее время, затраченное на выполнение различных задач с течением времени.
Представление Ганта : продолжительность и перекрытие группы доступности базы данных.
Просмотр кода : быстрый способ просмотра исходного кода группы доступности базы данных.
Содействие
Хотите помочь в создании Apache Airflow? Ознакомьтесь с нашей сопутствующей документацией.
Кто использует Apache Airflow?
Более 400 организаций используют Apache Airflow в дикой природе.
Кто обслуживает Apache Airflow?
Airflow — это работа сообщества, но основные коммиттеры / сопровождающие несут ответственность за рассмотрение и объединение PR, а также за ведение переговоров по запросам новых функций.Если вы хотите стать сопровождающим, ознакомьтесь с Apache Airflow. требования коммиттера.
Могу ли я использовать логотип Apache Airflow в своей презентации?
Да! Обязательно соблюдайте политику в отношении товарных знаков Apache Foundation и фирменный буклет Apache Airflow. Самые свежие логотипы можно найти в этом репозитории и на веб-сайте Apache Software Foundation.
Товары Airflow
Если вы хотели бы иметь наклейки, футболку и т. Д. Apache Airflow, обратите внимание на Магазин Redbubble.
Ссылки
Введение в Apache Airflow | Руководства по Apache Airflow
Если вы вообще занимаетесь инженерией данных, вы, вероятно, слышали об Apache Airflow. С момента своего создания в качестве проекта с открытым исходным кодом на AirBnb в 2015 году Airflow быстро стал золотым стандартом для инженерии данных, получая общественный вклад от людей из крупных организаций, таких как Bloomberg, Lyft, Robinhood и многих других.
Если вы просто промочили ноги, вам, вероятно, интересно, о чем идет речь.Мы здесь, чтобы познакомить вас с основными концепциями, которые вам нужно знать, чтобы начать работу с Airflow.
История
В 2015 году у Airbnb возникла проблема. Они росли как сумасшедшие, и у них был огромный объем данных, который только увеличивался. Чтобы достичь цели стать организацией, полностью управляемой данными, им пришлось увеличить свой штат инженеров по обработке данных, специалистов по обработке данных и аналитиков — всем им приходилось регулярно автоматизировать процессы, создавая запланированные пакетные задания.Чтобы удовлетворить потребность в надежном инструменте планирования, Максим Бошемин создал Airflow с открытым исходным кодом с идеей, что он позволит им быстро создавать, выполнять итерацию и контролировать свои конвейеры пакетных данных.
Со времени первого коммита Максима в то время Airflow прошел долгий путь. Проект присоединился к официальному инкубатору Apache Foundation в апреле 2016 года, где он жил и рос, пока не завершился 8 января 2019 года как проект верхнего уровня. Почти два года спустя, по состоянию на декабрь 2020 года, Airflow насчитывает более 1400 участников, 11230 совершает и 19800 звезд на Github.17 декабря 2020 года был выпущен Airflow 2.0, принесший с собой важные обновления и новые мощные функции. Airflow используется тысячами групп инженеров данных по всему миру и продолжает применяться по мере того, как сообщество становится сильнее.
Обзор
Apache Airflow — это платформа для программного создания, планирования и мониторинга рабочих процессов. Это полностью открытый исходный код, и он особенно полезен при проектировании и организации сложных конвейеров данных. Первоначально Airflow был создан для решения проблем, связанных с длительными задачами cron и массивными скриптами, но с тех пор он превратился в одну из самых мощных платформ конвейера данных с открытым исходным кодом.
Airflow имеет несколько ключевых преимуществ, а именно:
- Это динамично: Все, что вы можете делать в Python, вы можете делать в Airflow.
- Расширяемость: Airflow имеет готовые плагины для взаимодействия с наиболее распространенными внешними системами. При необходимости вы также можете создавать свои собственные плагины.
- Масштабируемость: Команды используют Airflow для выполнения тысяч различных задач в день.
В Airflow рабочие процессы построены и выражены как направленные ациклические графы (DAG), где каждый узел DAG представляет определенную задачу.Airflow разработан с учетом того, что все конвейеры данных лучше всего выражаются в виде кода, и поэтому является платформой, ориентированной на код, на которой вы можете быстро выполнять итерацию рабочих процессов. Эта философия проектирования, ориентированная на код, обеспечивает степень расширяемости, с которой не могут сравниться другие инструменты конвейера.
Примеры использования
Airflow можно использовать практически для любых конвейеров пакетных данных, и в сообществе существует масса задокументированных случаев использования. Благодаря своей расширяемости Airflow особенно эффективен для организации заданий со сложными зависимостями в нескольких внешних системах.
Например, на диаграмме ниже показан сложный вариант использования, который можно легко реализовать с помощью Airflow. Написав конвейеры в коде и используя множество доступных плагинов Airflow, вы можете интегрироваться с любым количеством различных зависимых систем с помощью единой платформы для оркестровки и мониторинга.
Если вас интересуют более конкретные примеры, вот несколько интересных вещей, которые мы видели, как люди делают с Airflow:
- Объединяйте ежедневные обновления отдела продаж от Salesforce для отправки ежедневного отчета руководству компании.
- Используйте Airflow для организации и запуска заданий машинного обучения, выполняемых на внешних кластерах Spark.
- Ежечасно загружать данные аналитики веб-сайтов / приложений в хранилище данных.
Мы более подробно обсуждаем варианты использования Airflow в нашем эпизоде подкаста здесь, если вы хотите погрузиться глубже!
Основные концепции
DAG
Направленный ациклический граф или DAG — это конвейер данных, определенный в коде Python. Каждая группа DAG представляет собой набор задач, которые вы хотите запустить, и организована таким образом, чтобы отображать отношения между задачами в пользовательском интерфейсе Airflow.При разбиении свойств DAG становится очевидным их полезность:
- Направленный: если существует несколько задач с зависимостями, каждая должна иметь по крайней мере одну определенную восходящую или нисходящую задачу.
- Ациклический: Задачи не могут создавать данные, которые ссылаются на себя. Это сделано для того, чтобы избежать бесконечных циклов.
- График: Все задачи изложены в четкой структуре с процессами, происходящими в четких точках, с установленными отношениями с другими задачами.
Например, на изображении ниже слева показан допустимый DAG с парой простых зависимостей, в отличие от недопустимого DAG справа, который не является ациклическим.
Для более подробного обзора групп DAG ознакомьтесь с нашим руководством «Введение в группы DAG».
Задачи
Задачи представляют каждый узел определенной группы DAG. Они представляют собой визуальные представления работы, выполняемой на каждом этапе рабочего процесса, при этом фактическая работа, которую они представляют, определяется операторами.
Операторы
Операторы являются строительными блоками Airflow и определяют фактическую работу, которую нужно выполнить. Их можно рассматривать как оболочку для отдельной задачи или узла группы доступности базы данных, которая определяет, как эта задача будет выполняться.Группы DAG следят за тем, чтобы операторы были запланированы и выполнялись в определенном порядке, в то время как операторы определяют работу, которая должна выполняться на каждом этапе процесса.
Есть три основные категории операторов:
Операторы определяются индивидуально, но они могут передавать информацию другим операторам с помощью XComs.
На высоком уровне объединенная система DAG, операторов и задач выглядит так:
Крючки
Хуки— это способ взаимодействия Airflow со сторонними системами.Они позволяют подключаться к внешним API и базам данных, таким как Hive, S3, GCS, MySQL, Postgres и т. Д. Они действуют как строительные блоки для операторов. Защищенная информация, такая как учетные данные для аутентификации, хранится вне ловушек — эта информация хранится через соединения Airflow в зашифрованной базе данных метаданных, которая находится в вашем экземпляре Airflow.
Провайдеры
Поставщики — это поддерживаемые сообществом пакеты, которые включают в себя все основные операторы и хуки для данной услуги (например,грамм. Amazon, Google, Salesforce и др.). Как часть Airflow 2.0 эти пакеты поставляются с несколькими отдельными, но связанными пакетами, и их можно напрямую установить в среду Airflow.
Для просмотра и поиска всех доступных провайдеров и модулей посетите Astronomer Registry, центр обнаружения и распространения интеграций Apache Airflow, созданный для агрегирования и управления лучшими частями экосистемы.
Плагины
ПлагиныAirflow представляют собой комбинацию ловушек и операторов, которые можно использовать для выполнения определенной задачи, например, для передачи данных из Salesforce в Redshift.Ознакомьтесь с нашей библиотекой плагинов Airflow с открытым исходным кодом, если вы хотите проверить, был ли нужный плагин уже создан сообществом.
Подключения
Connections — это место, где Airflow хранит информацию, которая позволяет вам подключаться к внешним системам, например учетные данные для аутентификации или токены API. Это управляется непосредственно из пользовательского интерфейса, а фактическая информация зашифровывается и хранится в виде метаданных в базовой базе данных Postgres или MySQL Airflow.
Учись, делая
Если вы хотите поиграть с Airflow на своем локальном компьютере, ознакомьтесь с нашим интерфейсом командной строки Astronomer — это открытый исходный код, и его можно использовать совершенно бесплатно.С помощью интерфейса командной строки вы можете развернуть Airflow локально и начать пачкать руки основными концепциями, упомянутыми выше, всего за несколько минут.
Как всегда, не стесняйтесь обращаться к нам, если у вас есть какие-либо вопросы или если мы можем чем-то помочь вам в вашем путешествии по Airflow!
Apache Airflow 2.0 Tutorial. Apache Airflow уже широко используется… | Томаш Урбашек | Apache Airflow
Apache Airflow уже является широко используемым инструментом для планирования конвейеров данных.Но грядущий Airflow 2.0 будет более масштабным, поскольку в нем будет реализовано множество новых функций.
Источник изображенияВ этом руководстве представлены пошаговые инструкции по всем ключевым концепциям Airflow 2.0 и возможным вариантам использования.
Apache Airflow — это платформа с открытым исходным кодом для запуска любого типа рабочего процесса. И под любым мы имеем в виду… любое! Airflow использует язык программирования Python для определения конвейеров. Пользователи могут в полной мере воспользоваться этим, используя цикл for для определения конвейеров, выполняя команды bash, используя любые внешние модули, такие как pandas, sklearn, библиотеки GCP или AWS для управления облачными сервисами и многое, многое другое.
Airflow — надежное решение, которому доверяют многие компании. Pinterest раньше сталкивался с некоторыми проблемами производительности и масштабируемости и имел дело с высокими затратами на обслуживание. GoDaddy имеет множество групп пакетной аналитики и обработки данных, которым нужен инструмент оркестровки и готовые операторы для построения конвейеров ETL. Компания DXC Technology выполнила проект клиента, который требовал массивного хранения данных, следовательно, требовался стабильный механизм оркестровки. Все эти проблемы были решены путем правильного развертывания Airflow.
Универсальность Airflow позволяет использовать его для планирования любых типов рабочих процессов. Apache Airflow может запускать специальные рабочие нагрузки, не связанные ни с каким расписанием или интервалом. Тем не менее, он лучше всего работает для конвейеров:
- , которые меняются медленно
- , относящиеся к временному интервалу
- , запланированные по времени
Под «медленными изменениями» мы подразумеваем, что после развертывания конвейера ожидается изменение от времени к время (дни / недели, а не часы или минуты).Это связано с отсутствием версионирования конвейеров Airflow. «Относится к временному интервалу» означает, что Airflow лучше всего подходит для обработки интервалов данных. Вот почему Airflow лучше всего работает, когда конвейеры запланированы на определенное время. Хотя можно запускать конвейеры вручную или с помощью внешних триггеров (например, через REST API).
Apache Airflow можно использовать для планирования:
- конвейеров ETL, которые извлекают данные из нескольких источников и запускают задания Spark или любые другие преобразования данных
- Обучающие модели машинного обучения
- Создание отчетов
- Резервное копирование и аналогичные операции DevOps
И многое другое! Вы даже можете написать конвейер для приготовления кофе каждые несколько часов, для этого потребуются некоторые индивидуальные интеграции, но это самая большая сила Airflow — это чистый Python, и все можно запрограммировать.
Если вы хотите узнать больше о вариантах использования Airflow, посмотрите следующие видеоролики Airflow Summit:
Давайте начнем с нескольких основных концепций Airflow!
Airflow DAG
Рабочие процессы определяются в Airflow с помощью DAG (направленных ациклических графиков) и представляют собой не что иное, как файл python. Один файл DAG может содержать несколько определений DAG, хотя рекомендуется сохранять по одному DAG для каждого файла.
Давайте посмотрим на пример DAG:
из воздушного потока.модели импортируют DAG
из airflow.utils.dates import days_agowith DAG (
"etl_sales_daily",
start_date = days_ago (1),
schedule_interval = None,
) как dag:
...
Прежде всего, определяется DAG уникальным dag_id , который должен быть уникальным во всем развертывании Airflow. Кроме того, для создания группы DAG необходимо указать:
-
schedule_interval— который определяет, когда следует запускать DAG. Это может быть объектtimedelta, напримерtimedelta (days = 2)или строковое выражение cron* * * * *.Это может бытьNone, и тогда DAG не будет запланирован Airflow, но его все равно можно будет запустить вручную или извне. -
start_date— дата (объект datetime), с которой DAG начнет работу. Это помогает запустить DAG для прошлых дат. Обычно для указания этого значения используется функцияdays_ago. Если дата находится в будущем, вы все равно можете активировать даг вручную.
Когда у нас есть этот базовый план, мы можем начать добавлять задачи в наш DAG:
из воздушного потока.модели импортируют DAG
из airflow.utils.dates импортируют days_ago
из airflow.operators.dummy_operator import DummyOperatorwith DAG (
"etl_sales_daily",
start_date = days_ago (1),
schedule_perator65 = None,
) as dagmy_perator = None,
) (task_id = "task_a")
task_b = DummyOperator (task_id = "task_b")
task_c = DummyOperator (task_id = "task_c")
task_d = DummyOperator (task_id = "task_d") task_a >> [task_b, task_c] >> task_d
Каждая задача в Airflow DAG определяется оператором (мы скоро рассмотрим более подробную информацию) и имеет свой собственный task_id , который должен быть уникальным в DAG.У каждой задачи есть набор зависимостей, которые определяют ее отношения с другими задачами. К ним относятся:
- Задачи восходящего направления — набор задач, которые будут выполняться перед этой конкретной задачей.
- Последующие задачи — набор задач, которые будут выполнены после этой задачи.
В нашем примере task_b и task_c ниже по течению от task_a . И соответственно task_a находится в восходящем направлении как task_b , так и task_c .Распространенным способом указания отношения между задачами является использование оператора >> , который работает для задач и набора задач (например, списка или наборов).
Вот как выглядит графическое представление этой группы DAG:
Кроме того, каждая задача может указывать trigger_rule , что позволяет пользователям еще больше усложнять отношения между задачами. Примеры правил триггеров:
-
all_success— это означает, что все задачи в восходящем потоке задачи должны быть выполнены до того, как Airflow попытается выполнить эту задачу -
one_success— одной успешной задачи в восходящем потоке достаточно, чтобы запустить задачу с это правило -
none_failed— каждая задача в восходящем потоке должна быть либо успешной, либо пропущенной, ни одной неудачной задаче не разрешено запускать эту задачу
Все это позволяет пользователям определять произвольно сложные рабочие процессы очень простым способом.
Код, используемый для создания этого DAG, доступен на gist
Операторы, датчики и крючки воздушного потока
Как уже упоминалось, каждая задача в Airflow DAG определяется оператором. Каждый оператор представляет собой питонический класс, который реализует метод execute , который инкапсулирует всю логику того, что выполняется. Операторы можно разделить на три категории:
- Операторы действий — например, BashOperator (выполняет любую команду bash), PythonOperator (выполняет функцию python) или TriggerDagRunOperator (запускает другой DAG).
- Операторы передачи — предназначены для передачи данных из одного места в другое, например GCSToGCSOperator, который копирует данные из одной корзины Google Cloud Storage в другую. Эти операторы представляют собой отдельную группу, поскольку они часто отслеживают состояние (данные сначала загружаются из исходного хранилища и сохраняются локально на машине, на которой запущен Airflow, а затем выгружаются в целевое хранилище).
- Датчики — это классы операторов, унаследованные от
BaseSensorOperatorи предназначенные для ожидания завершения операции.При реализации датчика пользователи должны реализовать методpoke, который затем вызывается специальным методомexecuteизBaseSensorOperator. Методpokeдолжен возвращать True или False. Датчик будет выполняться Airflow, пока не вернет значение True.
Airflow поставляется с несколькими встроенными операторами, такими как упомянутый BashOperator . Однако пользователи могут легко установить дополнительных операторов с помощью пакетов провайдеров. Таким образом, Airflow упрощает использование сотен операторов, которые позволяют пользователям легко интегрироваться с внешними сервисами, такими как Google Cloud Platform, Amazon Web Services или общими инструментами обработки данных, такими как Apache Spark.
Рядом с операторами Airflow имеет концепцию крючков. В то время как операторы предназначены для обеспечения возможности многократного использования для определения задач и создания групп DAG, обработчики предназначены для упрощения создания новых операторов.
Основное назначение перехватчиков — реализация уровня связи с внешней службой вместе с общими методами аутентификации и обработки ошибок.
Например, давайте предположим, что мы хотим интегрироваться с Google Cloud Storage и хотим создать оператора для создания корзин.Сначала мы должны реализовать GCSHook, который реализует метод create_bucket :
из airflow.hooks.base_hook import BaseHookclass GCSHook (BaseHook):
def __init __ (self, * args, ** kwargs):
super () .__ init __ ( )def create_bucket (self, bucket_name: str):
# Вот логика для создания сегментов GCS
...
Затем мы создаем GCSCreateBucketOperator, который создает экземпляр GCSHook в методе execute и вызывает соответствующий метод:
от воздушного потока.models.baseoperator import BaseOperatorclass GCSCreateBucketOperator (BaseOperator):
def __init __ (self, *, bucket_name: str, ** kwargs):
super () .__ init __ (** kwargs)
self.bucket_name = bucket_name def execute (self.bucket_name = bucket_name def execute (self) ):
hook = GCSHook ()
hook.create_bucket (self.bucket_name)
Делая это, мы достигаем большой возможности повторного использования. Во-первых, новый хук можно повторно использовать в других операторах (например, в операторах передачи). Затем оператор может использовать метод перехвата, но также добавить дополнительную логику, которая не связана строго с созданием корзины, например обработка ситуаций, когда корзина уже существует.
В общем, методы хуков должны предоставлять минимально возможные строительные блоки, из которых мы можем построить более сложную логику, которая инкапсулируется в операторе.
Ознакомьтесь с некоторыми советами и приемами по определению групп Airflow DAG.
XCom
В то время как целью перехватчиков является реализация уровня связи с внешними службами, цель XCom — реализовать механизм связи, который позволяет передавать информацию между задачами в DAG.
Фундаментальной частью XCom является базовая таблица метаданных (с тем же именем), которая работает как хранилище значений ключей.Ключ состоит из кортежа ( dag_id , task_id , execution_date , key ), где атрибут key является настраиваемой строкой (по умолчанию это return_value ). Сохраненное значение должно быть json-сериализуемым и относительно небольшим (допускается не более 48 КБ).
Это означает, что цель XCom — хранить метаданные, а не данные. Например, если у нас есть даг с task_a >> task_b и большой фрейм данных должен быть передан из task_a в task_b , тогда мы должны сохранить его где-нибудь в постоянном месте (сегмент хранилища, база данных и т. Д.) между этими задачами.Затем task_a должен загрузить данные в хранилище и записать в таблицу XCom информацию, где эти данные могут быть найдены, например, uri для хранилища или имя временной таблицы. Как только эта информация находится в таблице XCom, task_b может получить доступ к этому значению и извлечь данные из внешнего хранилища.
Во многих случаях это может звучать как дополнительная логика загрузки и выгрузки данных в операторах. Это правда. Но, прежде всего, именно здесь на помощь пришли ловушки — вы можете повторно использовать логику для хранения данных в самых разных местах.Во-вторых, есть возможность указать собственный сервер XCom. Таким образом, пользователи могут просто написать класс, который будет определять, как сериализовать данные перед их сохранением в таблице XCom и как десериализовать их при извлечении из базы метаданных. Это, например, позволяет пользователям автоматизировать логику сохранения фреймов данных, как мы описали в этой статье.
Airflow как распределенная система
Хотя Airflow можно запустить на одной машине, он полностью разработан для распределенного развертывания.Это потому, что Airflow состоит из отдельных частей:
- Scheduler — это мозг и сердце Airflow. Планировщик отвечает за анализ файлов DAG, управление состоянием базы данных и, как следует из названия, за планирование задач. Начиная с Airflow 2.0, пользователи могут запускать несколько планировщиков, чтобы обеспечить высокую доступность этого важного компонента.
- Webserver — веб-интерфейс Airflow, который позволяет управлять и контролировать DAG.
- Worker — рабочее приложение Celery, которое потребляет и выполняет задачи, запланированные планировщиком, при использовании исполнителя, подобного Celery (подробнее в следующем разделе).Возможно иметь много воркеров в разных местах (например, используя отдельные виртуальные машины или несколько подов кубернетов).
Все эти компоненты можно запустить с помощью команды airflow . И все они требуют доступа к базе метаданных Airflow, которая используется для хранения всей информации о DAG и задачах. Кроме того, и планировщику, и рабочему требуется доступ к одним и тем же файлам DAG. Вот почему мы вскоре обсудим подходы к распределению DAG позже, но сначала давайте узнаем об исполнителях Airflow.
Executors
Executor — один из важнейших компонентов Airflow, и он может быть настроен пользователями. Он определяет, где и как должны выполняться задачи Airflow. Исполнителя следует выбирать в соответствии с вашими потребностями, поскольку он определяет многие аспекты развертывания Airflow.
В настоящее время Airflow поддерживает следующих исполнителей:
-
LocalExecutor— выполняет задачи в отдельных процессах на одной машине. Это единственный нераспределенный исполнитель, готовый к производству.Он хорошо работает в относительно небольших развертываниях. -
CeleryExecutor— самый популярный производственный исполнитель, который использует внутреннюю систему очереди Celery. При использовании этого исполнителя пользователи могут развернуть несколько воркеров, которые читают задачи из очереди брокера (Redis или RabbitMQ), куда задачи отправляются планировщиком. Этот исполнитель может быть распределен между многими машинами, и пользователи могут использовать очереди, которые позволяют им указывать, какая задача должна быть выполнена и где. Это, например, полезно для направления сложных вычислительных задач более находчивым сотрудникам. -
KubernetesExecutor— еще один широко распространенный исполнитель, готовый к продакшну. Как следует из названия, для этого требуется кластер Kubernetes. При использовании этого исполнителя Airflow создаст новый модуль с экземпляром Airflow для запуска каждой задачи. Это создает дополнительные накладные расходы, которые могут быть проблематичными для краткосрочных задач. -
CeleryKubernetsExecutor— название говорит само за себя, этот исполнитель использует как CeleryExecutor, так и KubernetesExecutor. Когда пользователи выбирают этого исполнителя, они могут использовать специальную очередьkubernetes, чтобы указать, что конкретные задачи должны выполняться с помощью KubernetesExecutor.В противном случае задачи передаются работникам сельдерея. Таким образом, пользователи могут в полной мере воспользоваться горизонтальным автоматическим масштабированием рабочих модулей и возможностью делегировать длительные / вычислительные тяжелые задачиKubernetesExecutor. -
DebugExecutor— это программа-исполнитель отладки. Его основная цель — локальная отладка DAG. Это единственный исполнитель, который использует один процесс для выполнения всех задач. Таким образом, его легко использовать на уровне IDE, как описано в документации.
Образ Docker и диаграмма штурвала
Один из самых простых способов начать путешествие с Airflow — использовать официальный образ докера Apache Airflow.Это позволит вам поиграть с Airflow локально и узнать о нем больше. Это также упрощает развертывание Airflow. Вы можете использовать ванильный образ или запечь свой собственный:
- с использованием образа Airflow в качестве базового образа в вашем Dockerfile,
- с помощью инструмента Airflow Breeze для создания оптимизированного пользовательского образа, проверьте документацию, чтобы узнать о настройке производственных развертываний.
Образ Docker служит основой для диаграммы Helm производственного уровня, которая позволяет развертывать Airflow в кластере Kubernetes.Он развертывает все компоненты Airflow вместе с готовой поддержкой для горизонтального автоматического масштабирования рабочих с помощью KEDA. Итак, если вы планируете использовать Kubernetes для развертывания Airflow, то это рекомендуемый путь!
Распределение Airflow DAG
Когда мы обсуждали Airflow как распределенную систему, мы подчеркнули, что и планировщику, и рабочему нужен доступ к файлам DAG. Планировщику они нужны для создания представления DAG в базе данных и планирования их. С другой стороны, рабочие должны прочитать DAG, чтобы выполнить его.
Определенно неудобно загружать группы DAG вручную в развертывание каждый раз, когда меняются их определения. Вот почему вам необходимо разработать процесс распространения DAG.
Обычно он начинается с репозитория, в котором вы храните DAG. Таким образом, у вас будет история изменений, и сотрудничество между членами команды станет простым. Затем вы используете систему CI / CD для загрузки групп DAG в свое развертывание.
Одна из возможностей может заключаться в использовании общей файловой системы (например, AWS Elastic File System), к которой может получить доступ любой компонент Airflow.Хотя это может работать для небольших развертываний, известно, что этот тип распределения DAG влияет на производительность Airflow (время анализа DAG, задержка между задачами).
Другой — рекомендуемый — подход заключается в доставке групп DAG на тома каждого компонента. Этого можно добиться с помощью таких инструментов, как git-sync, который синхронизирует локальные репозитории с удаленными. Или с помощью такого решения, как gcs rsync или gcs fuse.
Другой способ распространения DAG — это встроить их в собственный образ Docker. Однако это означает, что вам нужно перестраивать его для каждого изменения DAG (или по расписанию), и вам нужно иметь возможность легко изменять изображение, используемое каждым из компонентов Airflow.
У нас есть больше полезного контента об Airflow 2.0! Например, ознакомьтесь с этой статьей о поставщиках Airflow.
Это сообщение в блоге было первоначально опубликовано по адресу https://www.polidea.com/blog/
Основы воздушного потока — Учебная документация по воздушному потоку
Что такое воздушный поток?
логотип воздушного потока
Airflow — это механизм рабочего процесса, что означает:
- Управление планированием и запуском заданий и конвейеров данных
- Обеспечивает правильный порядок заданий на основе зависимостей
- Управление распределением ограниченных ресурсов
- Предоставляет механизмы для отслеживания состояния заданий и восстановления после сбоя
Он очень универсален и может использоваться во многих областях:
Основные концепции воздушного потока
- Задача : определенная единица работы (в Airflow они называются операторами)
- Экземпляр задачи : индивидуальный запуск одной задачи.Экземпляры задач также имеют индикативное состояние, которое может быть «выполняется», «успешно», «не удалось», «пропущено», «готов к повторной попытке» и т. Д.
- DAG : Направленный ациклический граф, набор задач с явным порядком выполнения, началом и концом
- DAG run : индивидуальное выполнение / запуск DAG
Разоблачение DAG
Вершины и ребра (стрелки, соединяющие узлы) имеют порядок и направление, связанные с ними
каждый узел в группе доступности базы данных соответствует задаче, которая, в свою очередь, представляет собой некую обработку данных.Например:
Узел A может быть кодом для извлечения данных из API, узел B может быть кодом для анонимизации данных. Узел B может быть кодом для проверки отсутствия повторяющихся записей и т. Д.
Эти «конвейеры» являются ацикличными, поскольку им требуется точка завершения.
Зависимости
Каждая из вершин имеет определенное направление, которое показывает взаимосвязь между определенными узлами. Например, мы можем анонимизировать данные только после того, как они были извлечены из API.
Идемпотентность
Это одна из наиболее важных характеристик хорошей архитектуры ETL.
Когда мы говорим, что что-то идемпотентно, это означает, что оно даст тот же результат независимо от того, сколько раз это выполняется (т.е. результаты воспроизводимы).
Воспроизводимость особенно важна в средах с большим объемом данных, поскольку это гарантирует, что одни и те же входные данные всегда будут возвращать одни и те же выходные данные.
Компоненты воздушного потока
Apache Airflow состоит из 4 основных компонентов:
Веб-сервер
Графический интерфейс.Это приложение Flask, в котором вы можете отслеживать статус своих заданий и читать журналы из удаленного файлового хранилища (например, Azure Blobstorage).
Планировщик
Этот компонент отвечает за планирование заданий. Это многопоточный процесс Python, который использует объект DAGb, чтобы решить, какие задачи нужно запускать, когда и где.
Состояние задачи извлекается и обновляется из базы данных соответственно. Затем веб-сервер использует эти сохраненные состояния для отображения информации о задании.
Исполнитель
Механизм, выполняющий задачи.
Рабочий процесс в виде кода
Одним из основных преимуществ использования такой системы рабочих процессов, как Airflow, является то, что все это код, который делает ваши рабочие процессы поддерживаемыми, версионируемыми, тестируемыми и совместимыми.
Таким образом, ваши рабочие процессы становятся более понятными и удобными в обслуживании (атомарные задачи).
Не только ваш код динамичен, но и ваша инфраструктура.
Определение задач
Задачи определяются на основе абстракции Operators (см. Здесь документы Airflow), которые представляют одну идемпотентную задачу .
Лучшая практика — иметь атомарные операторы (т.е. могут работать сами по себе и им не нужно делить ресурсы между собой).
Вы можете выбрать среди;
-
БашОператор -
Оператор Python -
Электронная почта Оператор -
SimpleHttpOperator -
MySqlOperator(и другие БД)
Примеры:
t1 = BashOperator (task_id = 'print_date',
bash_command = 'дата,
даг = даг)
def print_context (ds, ** kwargs):
pprint (kwargs)
печать (ds)
return 'Все, что вы вернете, будет напечатано в журналах'
run_this = PythonOperator (
task_id = 'print_the_context',
provide_context = True,
python_callable = print_context,
даг = даг,
)
Сравнение Луиджи и Airflow
Луиджи
- Создано в Spotify (названо в честь сантехника)
- Открыт исходный код в конце 2012 г.
- GNU make для данных
Воздушный поток
- Команда данных Airbnb
- Открытый грунт 2015
- Инкубатор Apache, середина 2016 г.
- Трубопроводы ЭТЛ
Сходства
- Python проекты с открытым исходным кодом для конвейеров данных
- Интеграция с рядом источников (базы данных, файловые системы)
- Ошибка отслеживания, повторные попытки, успех
- Способность определять зависимости и выполнение
Отличия
- Поддержка планировщика: Airflow имеет встроенную поддержку с использованием планировщиков
- Масштабируемость: в прошлом у воздушного потока были проблемы со стабильностью
- Веб-интерфейсы
| Воздушный поток | Луиджи |
| ———————————————— | —————————————————————————— |
| Задача определяется dag_id определяется именем пользователя | Задача определяется именем задачи и параметрами |
| Повторные попытки выполнения задачи на основе определений | Решить, выполняется ли задача через ввод / вывод |
| Код задания работнику | Рабочие, запущенные файлом Python, в котором определены задачи |
| Централизованный планировщик (Celery раскручивает рабочих) | Централизованный планировщик, отвечающий за отправку задач дедупликации (на основе Tornado) |
Начало работы с Apache Airflow | Аднан Сиддики
Официальный сайт Credit AirflowВ этом посте я собираюсь обсудить Apache Airflow, систему управления рабочим процессом, разработанную Airbnb.
Ранее я обсуждал написание базовых конвейеров ETL на Bonobo. Bonobo отлично подходит для написания конвейеров ETL, но мир не только в написании конвейеров ETL для автоматизации. Есть и другие варианты использования, в которых вам нужно выполнять задачи в определенном порядке один раз или периодически. Например:
- Мониторинг заданий Cron
- передача данных из одного места в другое.
- Автоматизация операций DevOps.
- Периодическое получение данных с веб-сайтов и обновление базы данных для вашей потрясающей системы сравнения цен.
- Обработка данных для рекомендательных систем.
- Конвейеры машинного обучения.
Возможности безграничны.
Прежде чем мы перейдем к внедрению Airflow в наших системах, давайте обсудим, что на самом деле такое Airflow и его терминологию.
С веб-сайта:
Airflow — это платформа для программного создания, планирования и мониторинга рабочих процессов.
Используйте воздушный поток для создания рабочих процессов в виде ориентированных ациклических графов (DAG) задач.Планировщик воздушного потока выполняет ваши задачи на массиве рабочих, следуя указанным зависимостям. Богатые служебные программы командной строки упрощают выполнение сложных операций на DAG. Богатый пользовательский интерфейс позволяет легко визуализировать конвейеры, работающие в производственной среде, отслеживать прогресс и при необходимости устранять неполадки.
По сути, это помогает автоматизировать сценарии для выполнения задач. Airflow основан на Python, но вы можете выполнять программу независимо от языка. Например, на первом этапе вашего рабочего процесса необходимо выполнить программу на C ++ для анализа изображения, а затем программу на Python для передачи этой информации в S3.Возможности безграничны.
Из Википедии
В математике и информатике ориентированный ациклический граф (DAG / ˈdæɡ / (об этом звуке, послушайте)) — это конечный ориентированный граф без направленных циклов. То есть он состоит из конечного числа вершин и ребер, причем каждое ребро направлено от одной вершины к другой, так что нет возможности начать с любой вершины v и следовать последовательно направленной последовательности ребер, которая в конечном итоге снова возвращается к v. . Эквивалентно, DAG — это ориентированный граф, который имеет топологический порядок, последовательность вершин, так что каждое ребро направлено от более раннего к более позднему в последовательности.
Позвольте мне попытаться объяснить простыми словами: вы можете быть только сыном своего отца, но не наоборот. Хорошо, это неубедительно или странно, но я не мог найти лучшего примера, чтобы объяснить направленный цикл .
Airflow DAG (Источник: Apache Airflow)В Airflow все рабочие процессы являются DAG. Dag состоит из операторов. Оператор определяет отдельную задачу, которую необходимо выполнить. Доступны различные типы операторов (как указано на веб-сайте Airflow):
-
BashOperator— выполняет команду bash -
PythonOperator— вызывает произвольную функцию Python -
EmailOperator— отправляет электронное письмо -
SimpleHttpOperator— отправляет HTTP-запрос -
MySqlOperator,SqliteOperator,PostgresOperator,MsSqlOperator,OracleOperator,JdbcOperatorи т. Д.- выполняет команду SQL. -
Датчик— ждет определенное время, файл, строку базы данных, ключ S3 и т. д.
Вы также можете придумать собственный оператор в соответствии с вашими потребностями.
Airflow основан на Python. Лучше всего установить его с помощью инструмента pip .
pip install apache-airflow
Чтобы проверить, установлен ли он, запустите команду: airflow version , и она должна напечатать что-то вроде:
[2018-09-22 15: 59: 23,880] {__init__.py: 51} INFO - Использование исполнителя SequentialExecutor____________ _________________ | __ () _________ __ / __ / ________ ______ / | | _ / __ ___ / _ / _ __ / _ __ \ _ | / | / / ___ ___ | / _ / _ __ / _ / / / _ / / _ | / | / / _ / _ / | _ / _ / / _ / / _ / / _ / \ ____ / ____ / | __ / v1.10.0 Вам также необходимо установить mysqlclient , чтобы включить MySQL в свои рабочие процессы. Однако это необязательно.
pip install mysqlclient
Прежде чем что-либо запускать, создайте папку и установите ее как AIRFLOW_HOME .В моем случае это airflow_home . После создания вы вызовете команду export , чтобы указать ее в пути.
export AIRFLOW_HOME = 'pwd' airflow_home
Перед запуском команды export убедитесь, что вы находитесь в папке выше airflow_home . В airflow_home вы создадите другую папку для хранения DAG. Назовите его dags
Если вы установите load_examples = False , он не будет загружать примеры по умолчанию в веб-интерфейсе.
Теперь вам нужно вызвать airflow initdb в папке airflow_home . После этого создается airflow.cfg и unitests.cfg
airflow.db — это файл SQLite для хранения всей конфигурации, связанной с запуском рабочих процессов. airflow.cfg сохраняет все начальные настройки, чтобы все работало.
В этом файле вы можете увидеть параметр sql_alchemy_conn со значением ../airflow_home/airflow.db
При желании можно использовать MySQL. А пока оставьте только базовые настройки.
Пока все хорошо, теперь, не теряя времени, запустим веб-сервер.
веб-сервер воздушного потока
При запуске отображается экран, например:
2018-09-20 22: 36: 24,943] {__init__.py:51} ИНФОРМАЦИЯ - Использование исполнителя SequentialExecutor / anaconda3 / anaconda / lib / python3. 6 / site-packages / airflow / bin / cli.py: 1595: DeprecationWarning: параметр celeryd_concurrency в [celery] был переименован в worker_concurrency - использовалась старая настройка, но, пожалуйста, обновите конфигурацию.default = conf.get ('сельдерей', 'worker_concurrency')), ____________ _________________ | __ () _________ __ / __ / ________ ______ / | | _ / __ ___ / _ / _ __ / _ __ \ _ | / | / / ___ ___ | / _ / _ __ / _ / / / _ / / _ | / | / / _ / _ / | _ / _ / / _ / / _ / / _ / \ ____ / ____ / | __ / v1.10.0 [2018 -09-19 14: 21: 42,340] {__init__.py:57} ИНФОРМАЦИЯ - Использование исполнителя SequentialExecutor____________ _________________ | __ () _________ __ / __ / ________ ______ / | | _ / __ ___ / _ / _ __ / _ __ \ _ | / | / / ___ ___ | / _ / _ __ / _ / / / _ / / _ | / | / / _ / _ / | _ / _ / / _ / / _ / / _ / \ ____ / ____ / | __ // anaconda3 / anaconda / lib / python3.6 / site-packages / flask / exthook.py: 71: ExtDeprecationWarning: импорт flask.ext.cache устарел, используйте вместо него flask_cache..format (x = modname), ExtDeprecationWarning [2018-09-19 14: 21: 43,119] [48995] {models.py:167} ИНФОРМАЦИЯ - Заполнение DagBag из / Development / airflow_home / dags Запуск сервера Gunicorn с помощью: Workers: 4 syncHost: 0.0.0.0:8080 Теперь при посещении 0.0.0.0:8080 он показывает экран вроде:
Здесь вы можете увидеть несколько записей.Это пример, поставляемый с установкой Airflow. Вы можете отключить их, посетив файл airflow.cfg и установив load_examples на FALSE
DAG Runs сообщают, сколько раз был выполнен определенный DAG. Recent Tasks сообщает, какая задача из множества задач в группе DAG выполняется в данный момент и каков ее статус. Расписание похоже на то, которое вы использовали бы при планировании Cron, поэтому я не буду на нем акцентировать внимание на данный момент.Расписание отвечает, в какое время должна запускаться эта определенная группа DAG.
DAG (Graph View)Вот снимок экрана с DAG, который я создал и выполнил ранее. Вы можете видеть прямоугольные поля, представляющие задачу. Вы также можете увидеть поля разных цветов в правом верхнем углу серого поля с названиями: успешно , работает , не удалось и т. Д. Это легенды. На картинке выше вы можете видеть, что все поля имеют зеленую рамку, тем не менее, если вы не уверены, наведите указатель мыши на легенду успеха, и вы увидите экран, как показано ниже:
Возможно, вы заметили цвет фона / заливки этих полей, которые зеленый и тростниковый.В верхнем левом углу серого поля вы можете увидеть, почему они такого цвета, этот цвет фона представляет различные типы операторов, используемых в этой группе DAG. В этом случае мы используем BashOperator, и PythonOperator.
Мы рассмотрим базовый пример, чтобы увидеть, как он работает. Я объясню на примере. В папке dags , которая была ранее создана в airflow_home / , мы создадим наш первый образец DAG. Итак, я собираюсь создать файл с именем my_simple_dag.py
Самое первое, что вы собираетесь сделать после импорта, — это написать процедуры, которые будут выполнять функции задач для операторов . Мы будем использовать смесь BashOperator и PythonOperator .
import datetime as dtfrom airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operator.python_operator import PythonOperatordef greet ():
def reply ():
print ('Запись в файл')
с открытием ('path / to / file / greet.txt', 'a +', encoding = ' utf8 ') как f:
now = dt.datetime.now ()
t = now.strftime ("% Y-% m-% d% H:% M")
f.write (str (t) + '\ n')
return 'Greeted'
return 'Greet Responded Again'
Это две простые процедуры, которые ничего не делают, кроме возврата текста.Позже расскажу, зачем я что-то пишу в текстовом файле. Следующее, что я собираюсь сделать, это определить default_args и создать экземпляр DAG .
default_args = {
'owner': 'airflow',
'start_date': dt.datetime (2018, 9, 24, 10, 00, 00),
'concurrency': 1,
'retries': 0
} Здесь вы устанавливаете набор параметров в переменной default_args dict .
start_date сообщает, когда этот DAG должен начать выполнение рабочего процесса.Эта start_date может принадлежать прошлому. В моем случае это 22 сентября и 11 утра по всемирному координированному времени. Эта дата для меня уже прошла, потому что для меня уже 11:15 утра UTC . Вы всегда можете изменить этот параметр через файл airflow.cfg и установить свой собственный часовой пояс. На данный момент мне подходит UTC. Если вам все еще интересно, какое время использует Airflow, проверьте в правом верхнем углу веб-интерфейса Airflow, вы должны увидеть что-то вроде приведенного ниже. Вы можете использовать это как ссылку для планирования ваших задач.
повторяет попытки. Параметр пытается запустить DAG X несколько раз в случае неудачного выполнения. Параметр concurrency помогает определять количество процессов, которые необходимо использовать для выполнения нескольких групп DAG. Например, ваша группа обеспечения доступности баз данных должна запускать 4 предыдущих экземпляра, также называемых обратным заполнением, с интервалом в 10 минут (, я расскажу об этой сложной теме в ближайшее время, ), и вы установили параллелизм на 2 , затем 2 группы доступности базы данных будет запускаться за раз и выполнять в нем задачи.Если вы уже реализовали multiprocessing в своем Python, тогда вы должны чувствовать себя здесь как дома.
с DAG ('my_simple_dag',
default_args = default_args,
schedule_interval = '* / 10 * * * *',
) as dag:
opr_hello = BashOperator (task_id = 'say_Hi', 907mand 'echo "Привет !!"') opr_greet = PythonOperator (task_id = 'greet',
python_callable = greet)
opr_sleep = BashOperator (task_id = 'sleep_me',
bash_command = 'sleep 5')
opr_respond task_id = 'response',
python_callable = response)
opr_hello >> opr_greet >> opr_sleep >> opr_respond Теперь, используя диспетчер контекста, мы определяем DAG с его свойствами, первый параметр — это идентификатор dag, в нашем случае это my_simple_dag , второй параметр, который мы уже обсуждали, третий параметр — это то, что необходимо обсудить вместе с start_date , который упоминается в default_args .
В этом диспетчере контекста , вы назначаете операторов вместе с идентификаторами задач. В нашем случае эти операторы обозначены как: opr_hello opr_greet opr_sleep и opr_respond . Эти имена затем появляются в прямоугольных ячейках, о которых говорилось выше.
Прежде чем двигаться дальше, мне лучше обсудить DAG Runs и scheduler и какую роль они играют во всем рабочем процессе.
Что такое планировщик воздушного потока?
Airflow Scheduler — это процесс мониторинга, который выполняется все время и запускает выполнение задачи на основе schedule_interval и execution_date.
Что такое DagRun?
DagRun — это экземпляр группы DAG, который будет запускаться одновременно. Когда он запускается, все задачи внутри него будут выполнены.
Выше приведена диаграмма, которая может помочь определить DAGRun 🙂
Предположим, что start_date — сентября, 24 сентября 2018 12:00:00 PM UTC , и вы запустили DAG в 12:30:00 PM UTC с schedule_interval из * / 10 * * * * (через каждые 10 минут). При использовании тех же параметров default_args , описанных выше, следующие записи DAG будут запускаться мгновенно, одна за другой в нашем случае из-за параллелизма — 1 :
Почему это происходит? Что ж, вы несете за это ответственность. Airflow дает вам возможность обходить DAG. Процесс прохождения DAG-файлов называется Backfill. Фактически, процесс Backfill позволяет Airflow изменять некоторый статус всех DAG с момента его создания.Эта функция была предоставлена для сценариев, в которых вы запускаете группу DAG, которая запрашивает некоторую базу данных или API, например Google Analytics, для получения предыдущих данных и включения их в рабочий процесс. Даже если прошлых данных нет, Airflow все равно запустит их, чтобы сохранить состояние всего рабочего процесса без изменений.
После того, как будут запущены предыдущие группы DAG, следующая (та, которую вы собираетесь запустить) будет запущена в 12:40:00 по всемирному координированному времени. Помните, что какое бы расписание вы ни установили, DAG запускается ПОСЛЕ этого времени, в нашем случае, если он должен запускать после каждые 10 минут, он будет запускаться через 10 минут.
Давай поиграем с этим. Я включаю my_simple_dag и запускаю планировщик.
планировщик воздушного потока
Как только вы запустите, вы увидите следующий экран dag:
DAG со статусом «Выполняется» Некоторые задачи поставлены в очередь. Если вы нажмете на DAG Id, my_simple_dag , вы увидите экран, как показано ниже:
Обратите внимание на временную метку в столбце Run Id . Вы видите закономерность? Первый выполнен в 10:00, затем в 10:10, 10:20.Затем он останавливается, позвольте мне еще раз уточнить, что DAG запускается по прошествии 10 минут. Планировщик запустился в 10:30. так что заполнено прошло 3 с разницей в 10 мин интервала.
DAG с обратными засыпками и текущийDAG, который был выполнен для 10:30:00 AM UTC , на самом деле был выполнен в 10:40:00 AM UTC . Последняя запись DAGRun всегда будет на единицу минусом, чем Текущее время. В нашем случае машинное время было 10:40:00 AM UTC
DAG Tree ViewЕсли вы наведете курсор на один из кругов, вы увидите отметку времени перед Run: , которая сообщает время, когда он был выполнен.Вы можете видеть, что разница во времени у этих зеленых кружков составляет 10 минут. Древовидное представление немного сложно, но дает полную картину всего вашего рабочего процесса. В нашем случае он был запущен 4 раза и все задачи выполнены успешно, темно-зеленый цвет.
Вы можете избежать обратного заполнения двумя способами: вы устанавливаете start_date будущего или устанавливаете catchup = False в экземпляре DAG . Например, вы можете сделать что-то вроде следующего:
с DAG ('my_simple_dag',
catchup = False ,
default_args = default_args,
schedule_interval = '* / 10 * * * *',
# schedule_interval = Нет,
) as dag: Если установить catchup = False , тогда не имеет значения, принадлежит ли ваша start_date прошлому или нет.Он будет выполняться с текущего времени и продолжится. Установив end_date , вы можете заставить DAG перестать работать.
opr_hello >> opr_greet >> opr_sleep >> opr_respond
Строка, которую вы видите выше, сообщает отношения между операторами, следовательно, строит весь рабочий процесс. Побитовый оператор здесь сообщает отношения между операторами. Здесь сначала запускается opr_hello , а затем остальные. Поток выполняется слева направо.В графической форме это выглядит так:
opr_hello >> opr_greet >> opr_sleep << opr_respond
Если вы измените направление последнего оператора, поток будет выглядеть следующим образом:
Ответ задача будет выполнена параллельно и сна будет выполняться в обоих случаях.
В этом посте я обсудил, как можно внедрить комплексную систему рабочих процессов для планирования и автоматизации рабочих процессов. Во второй части я приведу реальный пример, чтобы показать, как можно использовать Airflow.